Synthesized’s Documentation
Synthesized provides the enterprise standard for data provisioning into non-production environments – enabling seamless access, transformation, and generation of data across environments from on-premises to cloud.
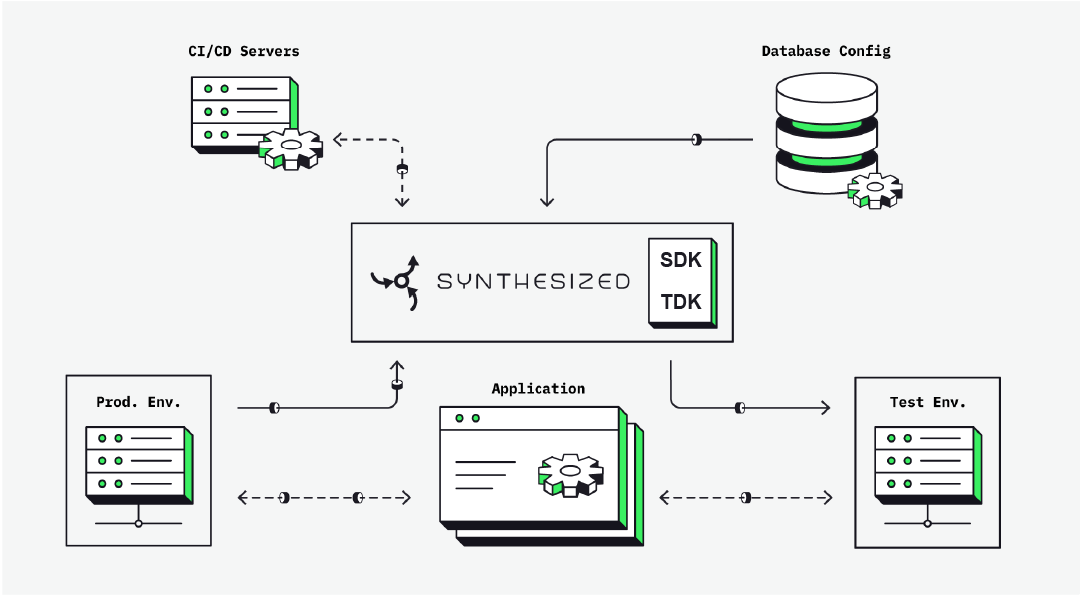
Synthesized’s Modules
Test Data Kit
For very large test data databases with complicated primary-foreign key relationships, our TDK is the tool to use.
-
Maintain referential integrity
-
Subset and mask databases
-
Generate privacy-preserving replicas
Community support for free versions of the TDK is available here.