Evaluation Report
Introduction
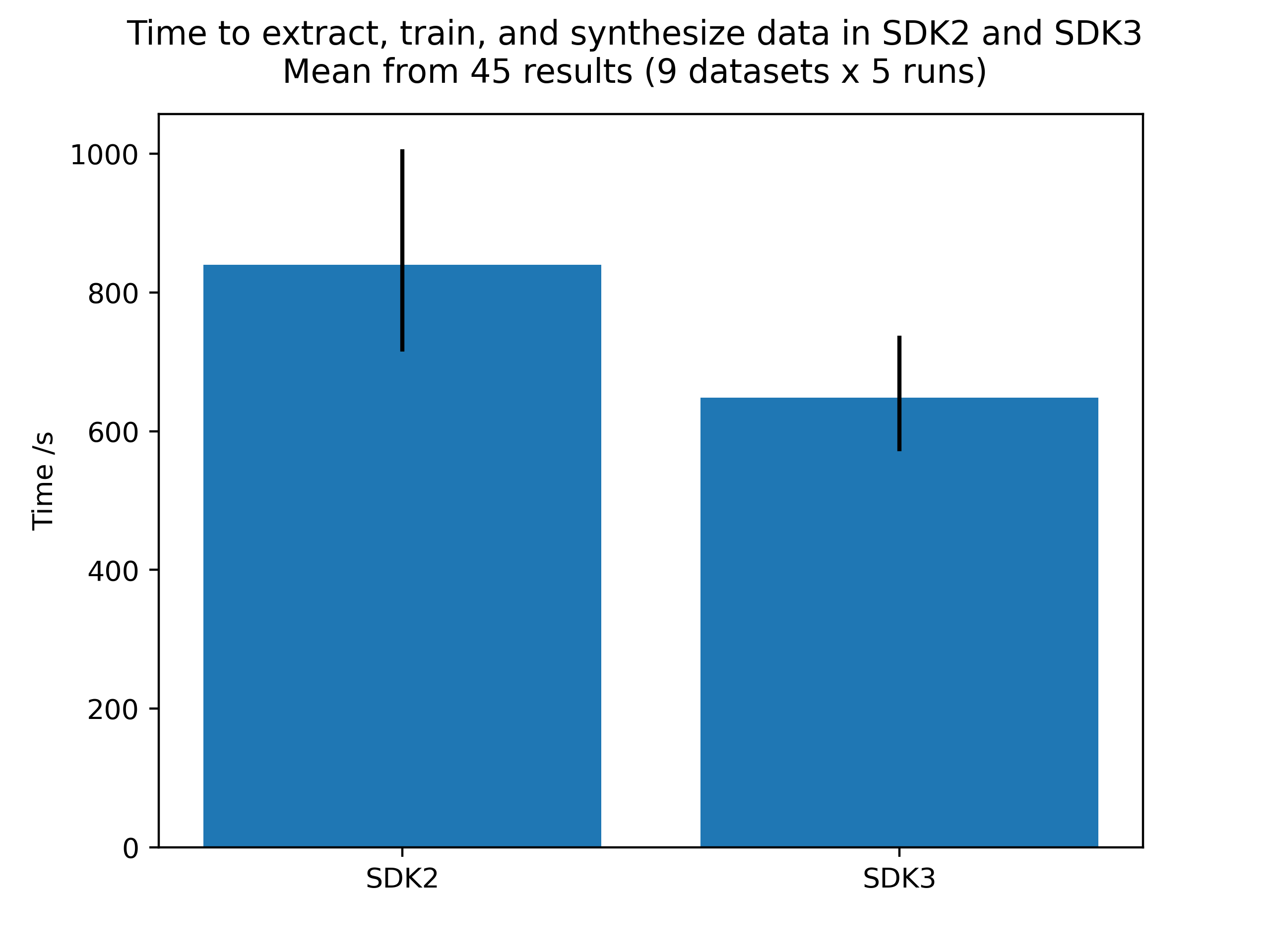
This section contains the results of an evaluation investigation comparing the performance of SDK3 to SDK2 using multiple datasets.
The SDK2 was run in its default mode, processing and synthesizing a Pandas dataframe. The SDK3 was run in Spark in single-node configuration in its default mode, processing and synthesizing a Spark dataframe.
Benchmarking process
To benchmark the performance of the SDKs, a full run was performed in an 'end-to-end' pipeline, i.e. dataset loaded, synthetic model created and trained, and the model used to generate 10,000 rows of synthetic data. The full 'end-to-end' cycle was performed (with metrics measured) five times in order to capture variance values for the metrics. This set of benchmarking was performed on nine different datasets to ensure performance was tested on a variety of data configurations (i.e. varieties of data types, numbers of rows, numbers of columns, numbers of continuous and categorical columns, etc). The datasets used were a subset of those available in the synthesized-datasets package, with direct links to those used below:
Finally, the results of all datasets were aggregated to give the final results, presented below.
All benchmarking results were run on the same machine with the following configuration:
-
OS: debian-11-bullseye-v20231010
-
Architecture: x86/64
-
Number of virtual CPUs: 4
-
RAM: 32 GB