Changelog
Version 2.12
3 May 2024
feature Greater locale configuration for Person annotation.
The Person annotation now supports configuring the locale of generated names, usernames, and email addresses via:
-
Specifying a single locale or list of locales to randomly select from in the annotation.
-
Specifying a country column in the DataFrame, containing country names, country codes or locales. The distribution of locales will be learnt from the column.
Version 2.10
16 February 2024
feature Generate locale-specific company entities
It’s now possible to generate company names and their associated countries using the Company
annotation. The annotation supports over 50 countries and their respective locales at this time.
See the documentation on annotations for more details.
feature Added TypoMask, WhiteSpaceMask, and AcronymMask
Added three new masks to the available masking transformations.
-
TypoMask: Introduces typos into a string. -
WhiteSpaceMask: Introduces random white space into a string. -
AcronymMask: Converts a string into an acronym with a specified delimiter.
Please see the privacy masks documentation for more details.
bug Integer overflow error in Histogram
When training the synthesizer on data with large positive and negative values, it was possible to cause an integer overflow error when calculating the range of the column. For example,
>>> import pandas as pd
>>> from synthesized import HighDimSynthesizer
>>> df = pd.Series([
... -8_000_000_000_000_000_000,
... 7_000_000_000_000_000_000,
... 8_000_000_000_000_000_000
... ], name='big_ints').to_frame()
>>> synth = HighDimSynthesizer.from_df(df)
Traceback (most recent call last):
...
File ".../site-packages/numpy/core/function_base.py", line 123, in linspace
raise ValueError("Number of samples, %s, must be non-negative." % num)
ValueError: Number of samples, -1, must be non-negative.This issue has been fixed in version 2.10.
Version 2.9
27 October 2023
feature Added DateShiftMask and TimeExtractionMask
Added two new masks to the available masking transformations.
-
DateShiftMask: Offsets a datetime column by a random amount of time. -
TimeExtractionMask: Extracts a particular component of a datetime as specified by the user.
Please see the privacy masks documentation for more details.
enhancement SynthOptimizer can now be run with default arguments
The SynthOptimizer can now be run with default arguments. Previously a build_and_train_function had to be supplied to the SynthOptimizer constructor. This is no longer required and, the default will pass the parameters argument to the HighDimSynthesizer constructor via a HighDimConfig object.
v2.8 |
v2.9 |
|
|
breaking change SynthOptimizer API change
Some arguments to the SynthOptimizer have been renamed:
v2.8 |
v2.9 |
|
|
|
|
breaking change callbacks parameter behaviour has been changed so default callbacks are always present
In order to enable a smoother user-specified callbacks procedure, the default internal Synthesized callbacks are now always present, including when users specify custom callbacks. Previously, if users specified custom callbacks these would override the default callbacks and, if users wanted to include the default callbacks, they would have to be included manually.
Version 2.8
13 September 2023
breaking change rules module has been moved to metadata.rules
In order to accommodate saving association rules as part of a configured HighDimSynthesizer
module, the rules module has been moved from common.rules to metadata.rules.
feature Public API wrapping the SDK functionality
The Python SDK now has a public API which wraps the functionality of the SDK. This API is
available in the synthesized.api module. The API is intended to be used by users who want to
use the SDK functionality with yaml configuration.
The API contains the following six functions:
import synthesized as syn
syn.api.train(df, config)
syn.api.generate(synth, config)
syn.api.serialize(synth)
syn.api.deserialize(data)
syn.api.synthesize(df, config)
syn.api.validate_config(config)Details of the config objects can be found in the YAML Configuration page.
feature Validate YAML config objects without file paths
Previously the Python SDK supported validating a YAML config by supplying a file path of the YAML config. However, if the config file had already been read into python, or if the config has been created in python, there was no way to validate it without writing the object to a temporary file location.
To address this, a new function has been added to synthesized.api which allows config objects to
be directly validated by the SDK.
v2.7 |
v2.8 |
|
|
feature Added HashingMask
Added the HashingMask class which can be used to mask sensitive data using a HMAC-SHA256
algorithm. Example usage is shown on the
privacy masks page.
enhancement EventSynthesizer and TimeSeriesSynthesizer objects can be serialized
The EventSynthesizer and TimeSeriesSynthesizer classes can now be saved to a file using the export_model() method.
with open('synth.bin', 'wb') as f:
synth.export_model(f)enhancement Support for Python 3.11
Synthesized now supports python 3.11 on Windows, MacOS and Linux.
enhancement Fixed user warning with QuantileTransformer
When using the QuantileTransformer to transform data, a user warning was being raised relating to missing feature names. This has been fixed.
breaking change EventSeriesSynthesizer and TimeSeriesSynthesizer API change
The training of the EventSynthesizer and TimeSeriesSynthesizer has changed
v2.7 |
v2.8 |
|
|
See the documentation for more details.
Version 2.7
30 June 2023
enhancement Improved HighDimSynthesizer training stability and synthetic data quality
The training stability of the HighDimSynthesizer and the synthetic data it generates has been improved.
enhancement Improved TimeSeriesSynthesizer synthetic data quality
The synthetic data generated by the TimeSeriesSynthesizer have been improved.
enhancement Add id_capacity, num_id_layers, and num_time_layers hyperparameters to DeepStateConfig
When using the TimeSeriesSynthesizer or EventSynthesizer three new hyperparameters can be configured: id_capacity, num_id_layers, and num_time_layers.
They allow for the fine tuning of the models for improved synthetic data quality.
Version 2.6
18 May 2023
feature Added TimeSeriesAssessor
The TimeSeriesAssessor class can be used to create plots of time-series data as well as
to investigate autocorrelation and seasonality in the data. For example:
from synthesized.testing import TimeSeriesAssessor
...
tsa = TimeSeriesAssessor(ts_synthesizer, df, df_synth, identifiers=["AAL", "AAPL"])
tsa.show_auto_associations()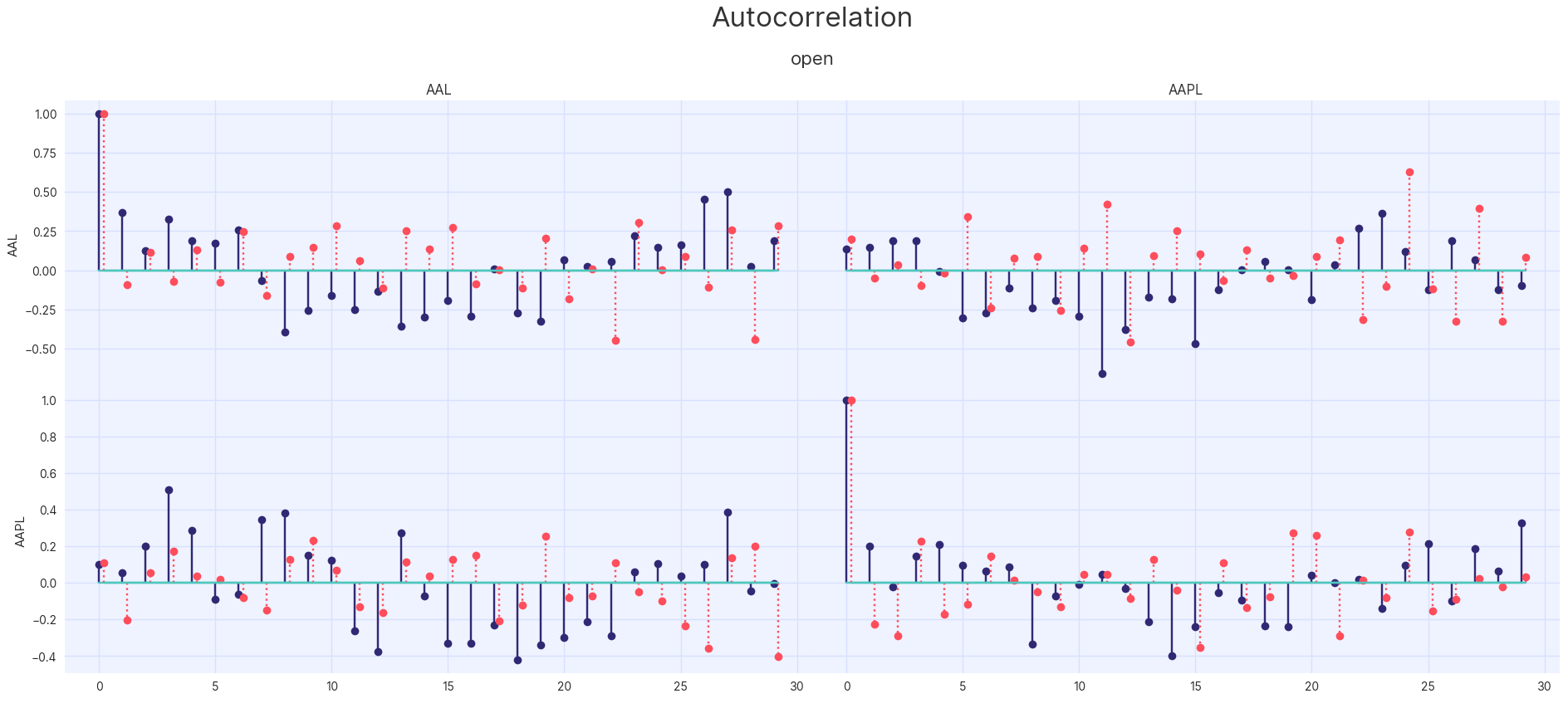
enhancement Improved preprocessing performance of TimeSeriesSynthesizer and EventSynthesizer
The preprocessing step of the TimeSeriesSynthesizer and EventSynthesizer has been improved
dramatically. This results in a much lower memory footprint and faster training times.
Version 2.5
31 March 2023
feature Ability to use the Expression class in the EventSynthesizer and TimeSeriesSynthesizer
When synthesizing time-series or event-based data, it is now possible to constrain the output such that deterministic relationships between columns are adhered to. For example, column C is the sum of columns A and B:
from synthesized.metadata.rules import Column, Expression
column = Column("A")
expression = Expression(column, "B+C")
df_synth = synth.synthesize(N, df_exogenous=df_exogenous, expression_rules=[expression])where synth is a trained TimeSeriesSynthesizer or EventSynthesizer instance. For more details on expressions and
their use see the Rules documentation.
enhancement Add low_memory flag to DeepStateConfig
When using the TimeSeriesSynthesizer or EventSynthesizer it is now possible to enter a low-memory mode through a flag
in the DeepStateConfig:
from synthesized import TimeSeriesSynthesizer
from synthesized.config import DeepStateConfig
config = DeepStateConfig(low_memory=True)
synth = TimeSeriesSynthesizer(
df,
id_idx=id_idx,
time_idx=time_idx,
event_cols=event_cols,
config=config
)Note that this may increase training and synthesis time for very large datasets.
enhancement Add shuffle flag to DeepStateConfig
When using the TimeSeriesSynthesizer or EventSynthesizer it is now possible to optionally shuffle the order that the
data for each unique entity is seen during the training of the model. When shuffle=True the order of the unique entities
in the training process will be fully randomised.
One use of setting shuffle=False is to lower the memory consumption during training.
enhancement Optionally downsample categories with high cardinality in EventSynthesizer
When using the EventSynthesizer on data with categorical columns with a high cardinality (that is, categorical columns containing many unique values), it is now possible to lower the
resource usage by indicating these columns as sample_cols in the initialization call. Internally, the numerous categories
are downsampled to a smaller effective number of categories. This is especially useful for the ID index which often contains
1000s of unique values.
from synthesized import EventSynthesizer
synth = EventSynthesizer(
df=df,
id_idx="account_id",
time_idx="date",
const_cols=["mean_income"],
event_cols=['amount', 'balance', 'bank', 'account']
sample_cols=["account_id", "account"]
) Version 2.4
17 March 2023
feature Generation of YAML configuration for CLI synthesis
Using -g option a default YAML configuration file can be generated for use in command line
synthesis. See YAML Configuration for the complete guide.
feature Ability to supply and overwrite columns when synthesizing event data
When synthesizing event data, it is now possible to supply a DataFrame containing columns that should be used to overwrite the columns in the synthesized data. For example:
df_overwrite
# a b
# 0 1 yes
# 1 2 yes
# 2 1 no
event_synthesizer.synthesize(
n=3,
df_overwrite=df_overwrite
)
# time a b c
# 0 2023-06-01 1 yes 3.2
# 1 2023-06-02 2 yes -1.1
# 2 2023-06-06 1 no 0.3As the data is synthesized, the columns in df_overwrite are used to constrain the generative
model output. This can be used to ensure that specific columns of the synthetic data
are identical to their original counterparts. (See in the above example columns a and b are
maintained in the output.)
enhancement Command line synthesis YAML configuration expanded
The parameters that can be configured in YAML when using the synthesized command line synthesis have been expanded. YAML configuration files will now be validated against a default schema, ensuring that the appropriate keywords and values dtypes have been provided. See YAML Configuration for the complete guide.
|
If a parameter is specified in the YAML config and also as a command line argument, then the command line argument will take priority. |
breaking change Names of Privacy Masks have changed
The names of the Privacy Masks has changed:
v2.3 |
v2.4 |
|
|
|
|
|
|
|
|
In addition, the name of the methods of MaskingFactory have also been changed:
v2.3 |
v2.4 |
|
|
|
|
|
|
breaking change Format of arguments to MaskingFactory have changed
When using the create_masks method of MaskingFactory (previously known as the
create_transformers method of the ` MaskingTransformerFactory`, see above) the format of the
config argument has been changed. All arguments are now provided in a dictionary, where
previously the | separator was used between the masking technique and associated value:
v2.3 |
v2.4 |
|
|
See the Privacy Masks documentation for more details.
breaking change API of MaskingTransformerFactory has changed
To create a set of masking transformers using the create_transformers method of the MaskingTransformerFactory the
DataFrame to be masked now needs to be supplied as an argument,
v2.3 |
v2.4 |
|
|
bug DataFrameTransformer returned by MaskingTransformerFactory not returning all columns
When calling transform on the DataFrameTransformer object returned by the create_transformers
method of MaskingTransformerFactory, only the masked columns were returned. This bug has now been
fixed such that all columns in the DataFrame passed to the transform method are now returned.
bug Incorrect Event Synthesis for datasets with almost regular events
Datasets that only have a few unique values when diffing the time_index (i.e.,
df["time_index"].diff().nunique()) were being incorrectly synthesized. In these circumstances,
all events for each entity were being synthesized to occur at the same time. This bug has now been
fixed.
Version 2.3
19 December 2022
Version 2.3 of the python SDK. (Wheel archive ).
enhancement Support for Python
Synthesized now supports python 3.7, 3.8, 3.9, and 3.10 on Windows, MacOS and Linux.
Version 2.2
24 November 2022
Version 2.2 of the python SDK. (Wheel archive ).
enhancement Dense Layers with Batch Normalisation don’t need Bias
Dense Layers can be described by
where are the weights and biases of the layer and is the activation function.
When batch normalisation is used, it’s applied before the activation function and normalises by the mean and standard deviation of the batch. Batch normalisation also scales the output with two learned parameters and , i.e.
The scaled is then passed to the activation function .
The expectation value of over a given batch, , is given by
Substituting this and the first equation in for the expression for gives
where the bias from the dense layer cancels
meaning the bias for a dense layer doesn’t affect the output when batch normalisation is used. Instead, the term acts as a bias.
This means that the dense layers with batch normalisation have the unnecessary overhead of learning a bias which will take more time to train and result in a larger overall model. This redundancy was addressed in this enhancement.
enhancement Use value_counts instead of Moving Average in CategoricalValue
Instead of calculating the moving average of categorical counts during training (which has fluctuations) we can get the categorical value counts once before training begins and set those values as constants during training.
This has three benefits:
-
It is faster to train. as we don’t calculate moving average.
-
It is more accurate as the counts from the entire dataframe aren’t just an estimate of the frequencies.
-
It allows us to JIT compile the model in tensorflow. The moving average layer was the only TensorFlow layer that could not be JIT compiled.
enhancement TensorFlow matrix multiplication speed-up
The performance of learning and synthesizing has been improved by utilizing TensorFlows'
compilation optimizations for matrix multiplication. This optimization requires configuration
changes and improves the HighDimSynthesizer, TimeSeriesSynthesizer and EventSynthesizer.
feature TimeSeriesSynthesizer for regular time series and EventSynthesizer for event-based synthesis
In addition to tabular data Synthesized now supports two more forms of data:
-
Time series: Synthesize regularly spaced time-series data.
-
Event data: Create synthetic event-based data.
import pandas as pd
from synthesized import TimeSeriesSynthesizer
df = pd.read_csv(...)
synth = TimeSeriesSynthesizer(
df,
id_idx="id",
time_idx="timestamp",
event_cols=["event"],
)
synth.fit(dataset, epochs=15, steps_per_epoch=5000)
synth.synthesize(200) feature Add .from_df() constructor to HighDimSynthesizer
As a shortcut to quickly create a HighDimSynthesizer from a
pandas.DataFrame, the .from_df() constructor has been added.
with |
with |
|
|
feature Optionally use StandardScalar instead of QuantileTransformer
Previously, the QuantileTransformer was always used when training any model. However,
this is an especially non-linear process and can negatively impact a model’s
ability to impute nan values. Now, it is possible to configure the
ContinuousTransformer to optionally use a StandardScalar instead of the
QuantileTransformer.
synth = HighDimSynthesizer(df_meta, config=HighDimConfig(quantile=False))feature Optionally show the training metrics with the progress callbacks
It is now possible to set 3 different levels of verbosity (0, 1, 2) for the training progress of HighDimSynthesizer
synth.learn(df, verbose=0)bug Histogram probabilities do not sum to 1
When synthesizing some forms of categorical data, an error was thrown due to the
Histogram module not pulling through the correct probabilities
for categories to appear. This has now been fixed.
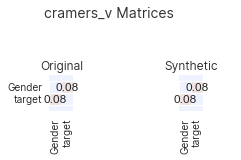
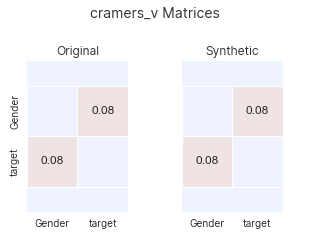
Version 2.1
5 August 2022
Version 2.1 of the python SDK. (Wheel archive ).
feature PyPI integration
Synthesized is now available for install via PyPI! See Installation.
feature 30 Day Trial Licence
Synthesized now supports a free 30 day trial licence which can be requested on import of synthesized or by running
the synth-validate cli command. See Setting the licence key.
Version 2.0
15 July 2022
Version 2.0 of the python SDK. (Wheel archive ).
enhancement Internal Framework Rebuild
With v2.0 the underlying framework of the SDK has been rebuilt, making it easier to extend in preparation for a wealth of new features planned for upcoming versions. The internal restructure paves the way for more native integration with a host of datasources, as well as providing some slight performance improvements with the majority of supported datatypes.
feature YAML configuration for command line synthesis
Previously in v1.10 a command line synthesis feature was added.
Moving towards greater integrations with CICD and process flows, YAML files can also be used to specify synthesis
feature options. This means all the Synthesized manipulations can be specified in an easy-to-write YAML file and
passed to the synthesize command above, allowing developers, devops engineers, data engineers, and the like to
write synthetic data specifications in clear YAML and run it without having to touch a line of python.
Specify a config file using the -c or --config flags followed by the name of the config file. i.e.:
$ synthesize -h
usage: synthesize [-h] [-c config.yaml] [-n N] [-s steps] [-o out_file] file
Create a synthetic copy of a given csv file.
positional arguments:
file The path to the original csv file.
optional arguments:
-h, --help show this help message and exit
-c config.yaml, --config config.yaml
Path to an optional yaml config file.
-n N The number of rows to synthesize. (default: The same
number as the original data)
-s steps The number of training steps. (default: Use learning
manager instead)
-o out_file, --output out_file
The destination path for the synthesized data.
(default: outputs to stdout)The YAML file structure should look something like:
---
annotations:
customer:
type: person
labels:
fullname: name
gender: sex
email: mail
username: username
type_overrides:
card_expire_date:
type: date_time
date_format: '%m/%y'
serial:
type: formatted_string
pattern: '\d{3}-\d{2}-\d{4}'
...breaking change Annotations
The config required for the Annotation files has been simplified. Where previously the input arguments ended in
_label, now the _label ending has been removed so just the keywords are required. Below is an example with the
Person annotations, but the change has been made for all annotations.
v1.11 |
v2.0 |
|
|
breaking change Produce NaNs
The default value for produce_nans has been changed from False to True.
Previously, the default behaviour of the SDK was to impute NaNs in the output data. After some consideration, it was
decided that the default behaviour should be to most accurately represent the raw input data, NaNs included, and that
imputation of NaNs is a special feature of the SDK that can be turned on at will.
To ensure NaNs are imputed in the output data in v2.0, produce_nans must now be manually set to True during
synthesis.
v1.11 |
v2.0 |
|
|
Version 1.11
24 April 2022
Version 1.11 of the python SDK. (Wheel archive ).
Version 1.10
14 April 2022
Version 1.10 of the python SDK. (Wheel archive ).
feature Simple time-series synthesis
We’ve been working hard to add more advanced time-series capabilities to the SDK. This release contains the initial framework for synthesizing and assessing time-series data.
Setting DataFrame indices
MetaExtractor.extract now has two optional arguments to specify which columns
are the ID & time indices.
import pandas as pd
from synthesized import MetaExtractor
df = pd.read_csv("https://raw.githubusercontent.com/synthesized-io/datasets/master/time-series/sandp500_5yr.csv")
df_meta = MetaExtractor.extract(df, id_index="Name", time_index="date")
df_meta.set_indices(df)The index of the DataFrame is a pd.MultiIndex and allows the DataFrame to
be neatly reformatted into a panel which cross sections can be taken from:
df.xs("AAL")Time-series plots
In order to plot and compare different time-series values for different entities, we can plot time
series with four different options of ShareSetting.
-
Entities share the same plot
ShareSetting.PLOT -
Entities have different plots but share the same x- and y-axis.
ShareSetting.AXIS -
Entities have different plots but share the same x-axis.
ShareSetting.X_AXIS -
No sharing. Each plot is independent.
ShareSetting.NONE
For example:
# Full script
import pandas as pd
from synthesized import MetaExtractor
from synthesized.testing.plotting.series import plot_multi_index_dataframes, ShareSetting
# Account IDs to plot
categories_to_plot = [2378, 576, 704, 3818, 1972]
# Columns to plot
continuous_ids = ["balance", "index"]
categorical_ids = ["bank", "k_symbol"]
ids = continuous_ids + categorical_ids
# Load data
df_categorical = pd.read_csv("https://raw.githubusercontent.com/synthesized-io/datasets/master/time-series/transactions_sample_10k.csv")
# Reduce data down to smaller volume for processing
df_categorical = df_categorical[df_categorical.type != "VYBER"]
df_categorical = df_categorical[ids + ["account_id", "date"]]
# Extract metadata
df_categorical_meta = MetaExtractor.extract(df_categorical, id_index="account_id", time_index="date")
# Plot dataframe
plot_multi_index_dataframes(df_categorical, df_categorical_meta, columns_to_plot=ids, categories_to_group_plots=categories_to_plot, share_setting=ShareSetting.AXES)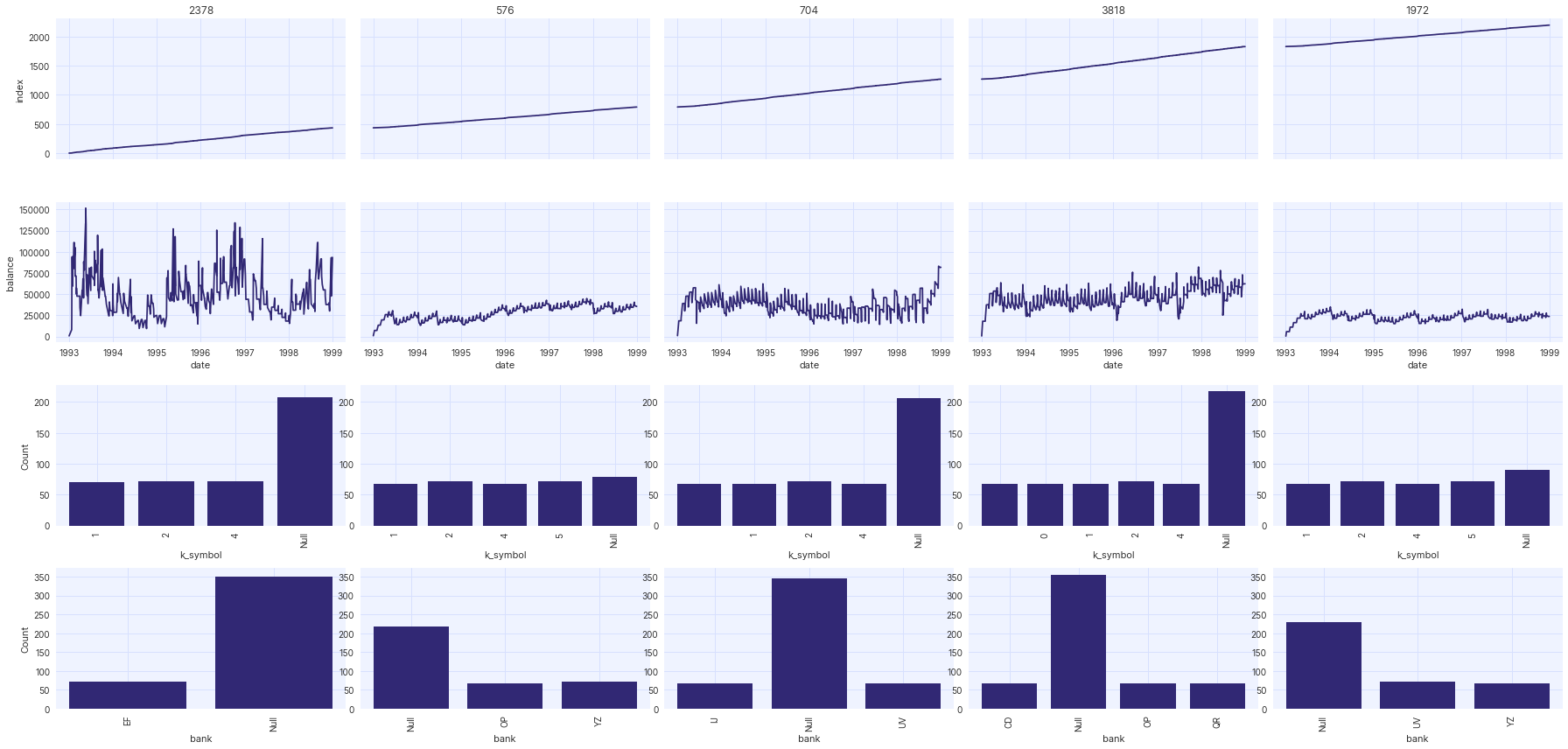
feature Synthesize from the command line
Calling synthesize after installing the SDK package with pip will allow users to create synthetic copies of csv data files from the command line.
Usage:
$ synthesize -h
usage: synthesize [-h] [-n N] [-s steps] [-o out_file] file
Create a synthetic copy of a given csv file.
positional arguments:
file The path to the original csv file.
optional arguments:
-h, --help show this help message and exit
-n N The number of rows to synthesize. (default: The same number as the
original data)
-s steps The number of training steps. (default: Use learning manager instead)
-o out_file, --output out_file
The destination path for the synthesized data. (default: outputs to
stdout)bug AttributeInferenceAttackML causes OOM issues with large categorical columns
The :class:`AttributeInferenceAttackML` has been optimized to avoid allocating excessively large amounts of memory when handling categorical columns. This resolves an issue where relatively small datasets would cause out of memory (OOM) issues.
bug Assessor doesn’t work with null columns
Previously, the :class:`Assessor` would fail when attempting to plot a dataset containing a completely empty column (NaNs only). This has been resolved.
The Assessor now returns an empty plot containing the text "NaN" for these columns.
bug Support FormatPreservingTransformer with MaskingTransformerFactory
Previously, there was no way to create
synthesized.privacy.FormatPreservingTransformer using
synthesized.privacy.MaskingTransformerFactory. Attempting to do so
would raise an error:
ValueError: Given masking technique 'format_preserving|[abc]{3}' for column '{column}' not supportedYou can now correctly create the Transformer with the MaskingDataFactory. For example:
mtf = MaskingTransformerFactory()
df_transformer = mtf.create_transformers({"col1": r"format_preserving|\d{3}"})
fp_transformer = dfm_trans._transformers[0]
assert isinstance(fp_transformer, FormatPreservingTransformer) # True Version 1.9
6 Feb 2022
Version 1.9 of the python SDK. (Wheel archive ).