What is the SDK?
The Scientific Data Kit (SDK) is a python package that can be used to generate high-quality synthetic data for uses in machine learning and data science tasks. After raw data is loaded into the SDK from a datasource, the highly optimised generative models utilised by the SDK are trained with this raw data. Once trained these models can synthesize a new dataset with the same statistical properties and correlations present in the original data. Additionally, the lack of a one-to-one mapping between original and synthetic data, as well as the robust privacy tools that can be enabled during the training and synthesis steps, enable the creation of datasets that are free of sensitive personally identifying information (PII). This ensures users can obtain access to representative data for machine learning tasks in a matter of minutes.
Who does the SDK help?
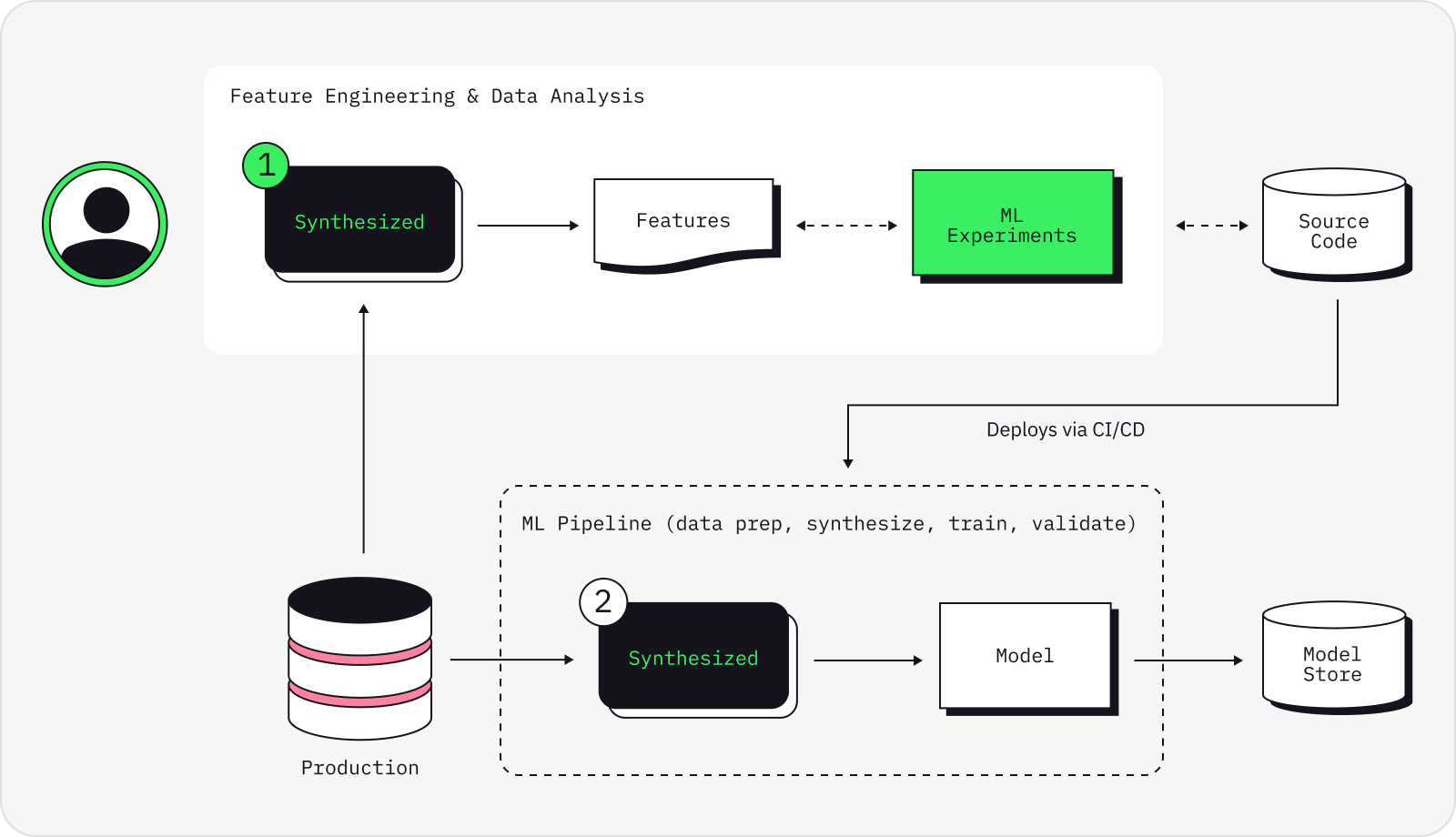
In short, anyone who requires quick access to trusted and secure data. As shown in the diagram below, the SDK can be utilised for two main use cases:
-
Engineers and researchers will often experience long delays when trying to access sensitive data, if they are ever granted access in the first place. This process of obtaining access to data that contains sensitive or personally identifiable information is both expensive and time-consuming, and ultimately reduces productivity and hinders development. With the use of the robust privacy measures built into the SDK and its highly optimised generative models, data engineers can easily access synthetic copies of real world data that enable rapid experimentation at scale.
-
On another front, data scientists will often face the issue of having low-quality data for machine learning model training. Real data can be highly unbalanced (where certain categories are present in tiny proportions in a dataset), or contain missing fields meaning that it has limited value when used to train machine learning models. The SDK can be used to improve machine learning model performance by generating a high-quality synthetic dataset, that is often better than production data, using techniques such as rebalancing, upsampling and data imputation. See below for more information.
In addition to preserving the statistical properties and correlations between columns in a tabular dataset, the SDK is also capable of handling time-series data where there are not only correlations between columns, but between sequences of events.
What does the SDK do?
Data Rebalancing: training data may contain fields with highly
imbalanced class variables, degrading overall model performance and potentially biasing the model against minority
subgroups within the data. With the use of the ConditionalSampler users can rebalance their data such that classes and
subgroups appear in the desired proportions, either by bootstrapping the original data with synthetic data or creating an
entirely synthetic data set with the desired distributions. This process amplifies the signal and reduces the noise present
in the original data, boosting model performance.
Data Imputation: training data quality is often degraded by missing values. Using
the DataImputer, users can impute missing values with synthetic data that will ensure the statistical properties of
the dataset are preserved.
Enhanced Privacy: the SDK offers a comprehensive range of privacy masks that can anonymize and obfuscate sensitive attributes in original data. When these privacy transformations are combined with synthetic data generation, the result is a synthetic dataset in which there are no one-to-one mappings to any point in the original data. Mathematical techniques such as differential privacy are also available for use in the data generation process to ensure robustness against more complex attacks, such as linkage attacks and attribute disclosure. The compliance features available as part of the SDK can provide easier access to data for data engineers and better guard sensitive information in the original production data.
For a full list of features, see our documentation on Data Quality Automation, Data Compliance Automation and Data Evaluation.
How does the SDK work?
The SDK is a python package available on PyPI, meaning that installing it in your local environment is a straightforward procedure. From this point, the SDK is available for use on your local machine in a jupyter notebook environment, or through the command line where the SDK can be run and configured using YAML.
Furthermore, the API-driven approach of the SDK allows it to seamlessly integrate with and extend various data platforms and ETL pipelines, including Airflow, Spark and Data Proc. Additionally, the pre-built docker image ensures the SDK is ready to deploy on a Kubernetes clusters with minimal setup required.