Hyperparameter Tuning
|
The full source code for this example is available for download here. |
Prerequisites
This tutorial assumes that you have already installed the Synthesized package, including the tune module. The tune module
can be installed through:
pip install synthesized[tune]If you are new to Synthesized, it is recommended you start with the quickstart guide and/or single table synthesis tutorial before jumping into this tutorial.
Introduction
Hyperparameter tuning is the process of finding the best set of hyperparameters for a machine learning model. For a
synthetic data model this means finding the set of parameters that produce the highest quality synthetic data.
The SynthOptimizer class handles this process for you. It has very straightforward default usage, as well as the
flexibility to be targeted towards a more specific use case.
This tutorial demonstrates the ability to perform hyperparameter optimisation for the HighDimSynthesizer model, although
the process is very similar for the TimeSeriesSynthesizer model. A custom loss function
and a custom build and train function are used to illustrate how the tuning process can be run for a specific use case.
A public credit scoring dataset from Kaggle, also available
from the synthesized.util module as an example dataset to train the synthetic data model.
import synthesized
data = synthesized.util.get_example_data()Possible Hyperparameters
When using the HighDimSynthesizer or TimeSeriesSynthesizer model, the following hyperparameters are available:
-
HighDimSynthesizer
-
TimeSeriesSynthesizer
-
"latent_size"(int): The size of the latent space within which the data representation is learned. Larger, more complex datasets with many columns may require a larger latent space. -
"capacity"(int): The capacity of the model. This is a proxy for the complexity of the relationships between data features that the model can learn. More complex and interdependent datasets may require increased capacity. -
"learning_rate"(float): The learning rate of the deep model fitting. -
"batch_size"(int): The batch size used for training. -
"weight_decay"(float): The weight decay used for training. -
"num_layers"(int): The number of layers in the networks of the model. -
"continuous_weight"(float): The relative weight of the continuous loss. -
"categorical_weight"(float): The relative weight of the categorical loss.
-
"latent_size"(int) The size of the latent space within which the data representation is learned. Larger, more complex datasets with many columns may require a larger latent space. -
"capacity"(int): The capacity of the model. This is a proxy for the complexity of the relationships between data features that the model can learn. More complex and interdependent datasets may require increased capacity. -
"num_time_layers"(int): The number of deep layers dedicated to modelling the time dimension. -
"num_id_layers"(int): Th number of deep layers dedicated to the identification of each individual timeseries in the dataset. -
"id_capacity"(int): The capacity allocated to modelling the identification of each individual timeseries in the dataset. -
"learning_rate"(float): The learning rate of the deep model fitting. -
"batch_size"(int): The batch size used for training. -
"max_time_steps"(int): The maximum number of time steps that the model should learn. -
"dropout_rate"(float): The dropout rate used for training.
Defining the hyperparameter search space
The first step is to define the search space over each of the hyperparameters chosen for investigate. The total search space is defined as a list of parameter dictionaries. The search space for a single hyperparameter is defined by a dictionary with the following key-value pairs:
Required elements:
-
"name"name of parameter, (string) -
"type"type of search strategy:"range","fixed", or"choice", (string)
and one of the following:
-
"bounds"for range parameters (list of two values, lower bound first) -
"values"for choice parameters (list of values) -
"value"for fixed parameters (single value).
Optional elements:
-
"log_scale"for float-valued range parameters, (bool), -
"value_type"to specify type that values of this parameter should take; expects"float","int","bool"or"str". -
"is_fidelity"(bool) and"target_value"(float) for fidelity parameters. -
"is_ordered"for choice parameters (bool). -
"is_task"for task parameters (bool). -
"digits"(int) for float-valued range parameters.
In this example, a small search space with a two hyperparameters, capacity and latent_size, is built:
parameters = [
{"name": "capacity", "type": "range", "bounds": [32, 64], "value_type": "int"},
{"name": "latent_size", "type": "range", "bounds": [32, 64], "value_type": "int"},
]Running the hyperparameter search
The hyperparameter search using the SynthOptimizer class can now be run. This class takes the following arguments:
Required arguments:
-
orig_df(pd.DataFrame): The original dataset, to train the synthetic model on. -
parameters(list): The list of hyperparameter dictionaries.
Optional arguments:
-
build_and_train_function(function): The function that constructs and trains the synthetic model. If not provided then a default model is built and trained. -
synthetic_model(string): The type of model that will be built by default, ifbuild_and_train_functionis not provided. This can take the values"HighDimSynthesizer"or"TimeSeriesSynthesizer". By default this is"HighDimSynthesizer". -
loss_name(string): The name of the loss metric to use for the hyperparameter search. -
custom_loss_function(function): The function that computes the loss of the synthetic model. -
max_parallelism(int): The maximum number of parallel processes (models trained in parallel) to use for the hyperparameter search. -
num_cpus(int): The number of CPUs to use for the hyperparameter search (per parallel process).
See below for more details on how to specify a custom build_and_train_function. Where build_and_train_function is not
specified the default process of model creation and metadata extraction is carried out, as described in the
single table synthesis tutorial.
|
If N cpus are available, |
To initialize the hyperparameter search provide the original dataset and the hyperparameter search space:
from synthesized.tune import SynthOptimizer
optimizer = SynthOptimizer(
orig_df=data,
parameters=parameters,
max_parallelism=4,
num_cpus=2
)To run the optimizer, call the optimize method. This method only takes one argument - the number of trials.
Ideally the number of trials should be greater than 10 but will be dependent on the size of the search space.
optimizer.optimize(20)A logging window will be displayed showing the progress of the hyperparameter search:
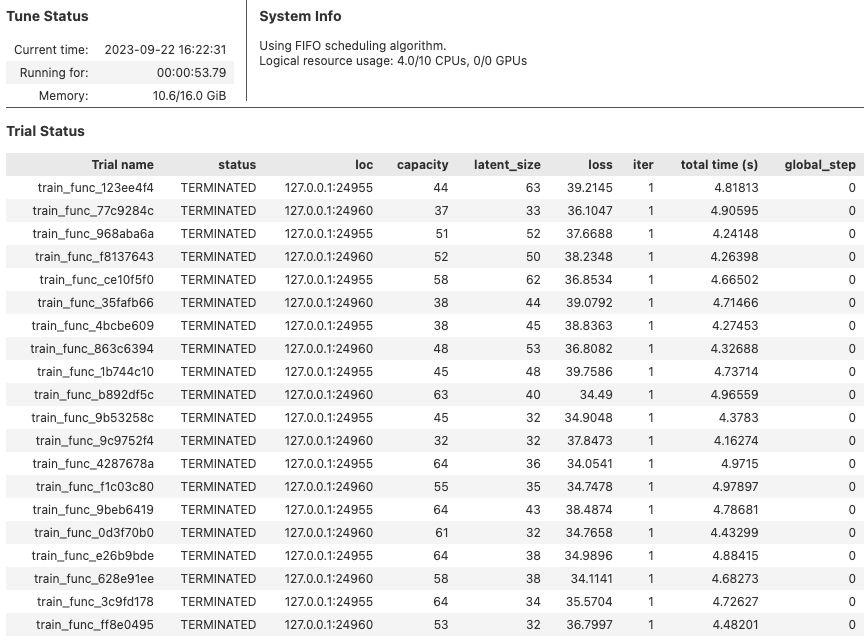
Hyperparameter search results
Once the hyperparameter search has completed, the SynthesizerOptimizer will contain the results of the search. SynthesizerOptimizer
provides useful utility methods for accessing and visualising the results. The method optimizer.plot_results() is called to visualize the results.
This will produce 4 useful plots that help in understanding the results of the hyperparameter search.
|
It is only possible to generate or visualize results if the |
optimizer.plot_results()The first is the feature importance:
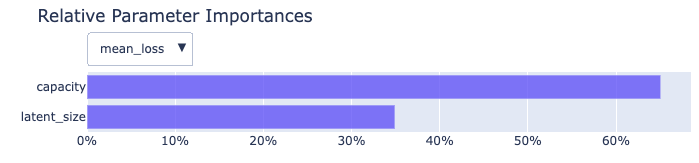
This shows the relative importance of each hyperparameter in the search, based on the parameter’s impact on the loss.
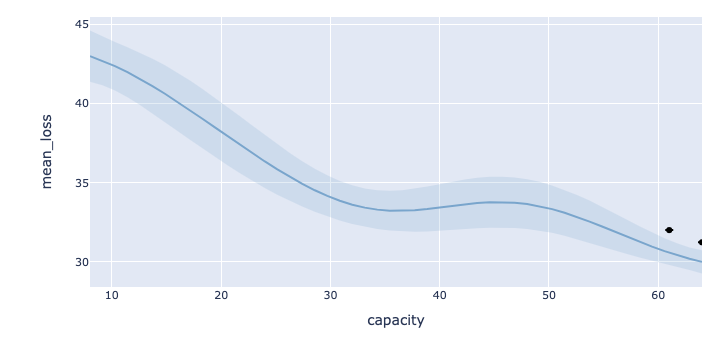
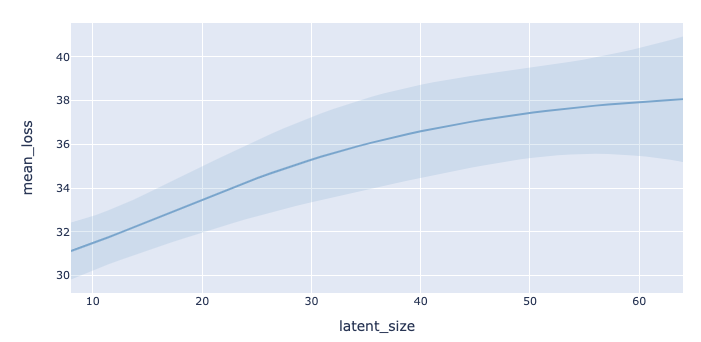
The second plot shows the loss as a function of each hyperparameter in the search range. This plot can be useful to understand where the optimum lies with respect to each hyperparameter, for example if the optimum lies at the edge of the search range for a given hyperparameter, it may be worth extending the search range for that hyperparameter. The blue boundaries around the distribution show an uncertainty estimate on the loss:
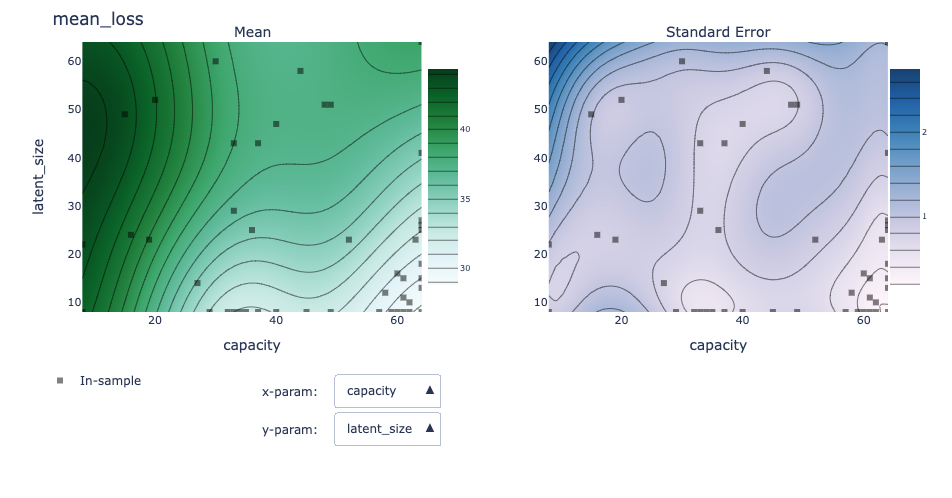
The third plot shows 2D distributions for combinations of parameters in terms of their impact on the loss and the uncertainty about the loss. This can be useful to understand relationships between hyperparameters.
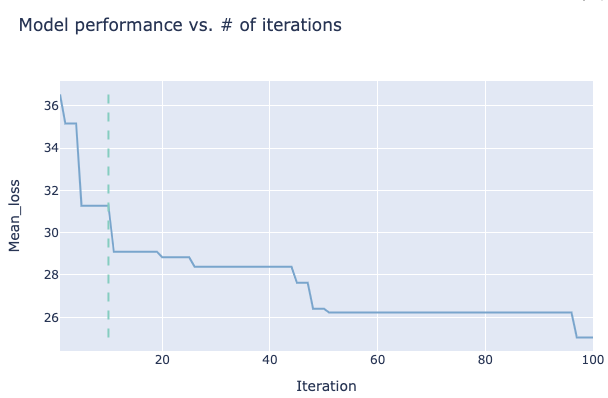
The final plot shows the loss as a function of the number of trials. This can be useful to give an impression on how big an impact the hyperparameter tuning is having and whether it is necessary running more trials.
Best hyperparameters
Finally, the best hyperparameters are retrieved from the optimizer using the get_best_params() method. The output of this method is a dictionary containing a few bits of key information:
-
params_raw- The best hyperparameters that were observed during the hyperparameter search. -
params_raw_mean_value- The mean value of the loss metric for the best hyperparameters. -
params_estimate- The estimated optimal parameters based on the hyperparameter search results. These may not have been observed during the hyperparameter search, but are implied from the results. -
params_estimate_mean_value- The mean value of the loss metric for the estimated optimal hyperparameters. -
params_estimate_variance- The variance of the loss metric for the estimated optimal hyperparameters.
optimizer.get_best_params()
The results of all the trials can be displayed as a dataframe using the get_trial_results_as_df() method:
optimizer.get_trial_results_as_df()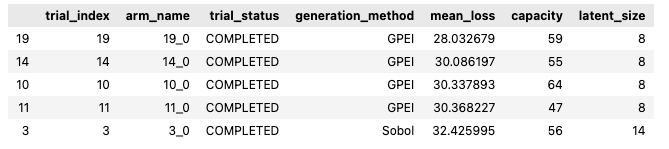
Advanced usage
Custom loss function
In some cases, there may be a specific and measurable evaluation metric for the synthetic data being generated. In these cases it is possible to define a custom loss function to use for the hyperparameter search that will specifically evaluate the synthetic data quality for the use case.
In this example, the synthetic data will be used to train a downstream classifier model. A custom loss function can then be defined to train the classifier on the synthetic data and evaluate its performance on real data (a process known as train-synthetic-test-real).
A custom loss function can be passed as an argument to SynthOptimizer to use it in the hyperparameter optimisation.
This function must take two inputs; the trained synthetic model and the original dataset. It must return a dictionary mapping
the metric name (string) to its value (float). Note that the SynthOptimizer class will always attempt to minimise the loss function, so if you
wish to maximise a metric the function should return the negative of that metric.
An example implementation for a custom loss function that trains a classifier on the synthetic data and evaluates its performance is shown below:
import pandas as pd
from synthesized import HighDimSynthesizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score
def custom_loss_function(synth: HighDimSynthesizer, orig_df: pd.DataFrame):
# drop nans
orig_df_no_nan = orig_df.dropna()
# Generate synthetic data
# Don't produce nans for logistic regression
synthetic_data = synth.sample(len(orig_df), produce_nans=False)
# Train a classifier on the synthetic data
model = LogisticRegression()
X_train = synthetic_data.drop(columns=["SeriousDlqin2yrs"])
y_train = synthetic_data["SeriousDlqin2yrs"]
# Evaluate the model on the original data
X_test = orig_df_no_nan.drop(columns=["SeriousDlqin2yrs"])
y_test = orig_df_no_nan["SeriousDlqin2yrs"]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
return {
"accuracy_score": - accuracy_score(y_test, y_pred),
"precision_score": - precision_score(y_test, y_pred),
"recall_score": - recall_score(y_test, y_pred),
}This custom loss function can then be passed to the SynthOptimizer class and the optimization run as before. The
function returns a dictionary of metrics about the model classifier performance. All these metrics are tracked in
the optimisation but only the accuracy is optimized for. The metric to be optimized for is passed in as the value of loss_name
to the SynthOptimizer:
optimizer = SynthOptimizer(
orig_df=data,
parameters=parameters,
custom_loss_function=custom_loss_function,
loss_name="accuracy_score",
)
optimizer.optimize(20)Custom build and train function
Analogous to defining a custom loss function, it is also possible to customize the manner in which the model is initialized and trained.
The SynthOptimizer class can be used to pass a custom build and train function to the optimizer. This function must take the following arguments:
-
parameters(dict): A dictionary of hyperparameters to use for the synthetic model. -
orig_df(pd.DataFrame): The original dataset, to train the synthetic model on.
and must return a trained synthetic model. As an example, a function called build_and_train_function can be used to create
and train an instance of the TimeSeriesSynthesizer where max_time_steps is fixed and the number of epochs the model
is trained over and the batch size per training step is optimized for:
from synthesized import TimeSeriesSynthesizer
from synthesized.config import DeepStateConfig
parameters = [
{"name": "epochs", "type": "range", "bounds": [5, 15], "value_type": "int"},
{"name": "batch_size", "type": "range", "bounds": [2, 10], "value_type": "int"}
]
df_time_series = df = pd.read_csv("sp_500_subset.csv")
def build_and_train_function(parameters, orig_df):
config = DeepStateConfig(max_time_steps=50, batch_size=parameters["batch_size"])
synth = TimeSeriesSynthesizer(
df,
id_idx="Name",
time_idx="date",
event_cols=["open", "close", "high", "low", "volume"],
config=config
)
synth.learn(epochs=parameters["epochs"])
return synth(The dataset "sp_500_subset.csv" is available for download in the time-series tutorial).
The build and train function is then passed to the SynthOptimizer class as an argument:
optimizer = SynthOptimizer(
orig_df=df_time_series,
parameters=parameters,
build_and_train_function=build_and_train_function,
)
optimizer.optimize(20)For more information on the use of the TimeSeriesSynthesizer see our time-series synthesis tutorial.