Data Compliance Automation
Compliance and security issues can mean that the process of gaining access to production data for ML experiments or testing purposes can be a lengthy and costly process, disrupting the workflow of data engineers and increasing the lead time of projects. Furthermore, once data access is granted it may prove that the dataset is inappropriate for an engineers needs, meaning the whole process of gaining data access must be restarted.
The concerns regarding the presence of sensitive information in data pipelines can be alleviated
through the use of synthetic data. Synthetic data (such as the data generated by the
HighDimSynthesizer), prevents certain privacy attacks as there is no 1-1 mapping
between the original data and the synthetic. A range of tools are available as part of the SDK
that can be combined in an extensible manner in order to deal with various types of sensitive information:
| Privacy Tool Guide | Description |
|---|---|
Annotations provide the ability to link multiple related columns and synthesize realistic data as a whole. |
|
The package provides methods for Differential Privacy which enforce mathematical guarantees on the privacy of the generated data. |
|
The privacy masking tools allow for more conventional methods of privacy preservation to be combined with Synthetic data. |
|
The |
Anonymization and Synthetic Data
Synthesized provides a comprehensive toolset to generate synthetic data that can be efficiently used for development and testing purposes. When deciding what tools to use when generating synthetic data, it is important to understand the types of sensitive data present in the original dataset.
There are typically three common types of data classifications:
-
1. Client Identifying Data or Personally Identifiable Information (CID or PII data) or data handled as CID/PII
-
Cat:A Direct CID/PII
-
Cat:B Indirect sensitive ID for CID/PII
-
Cat:C CID/PII resulting from a combination of multiple attributes (e.g. Bank Sort Code + Bank Account Number)
-
2. Cat:D Non-sensitive, identifier for CID/PII
-
3. Cat:E Non-CID
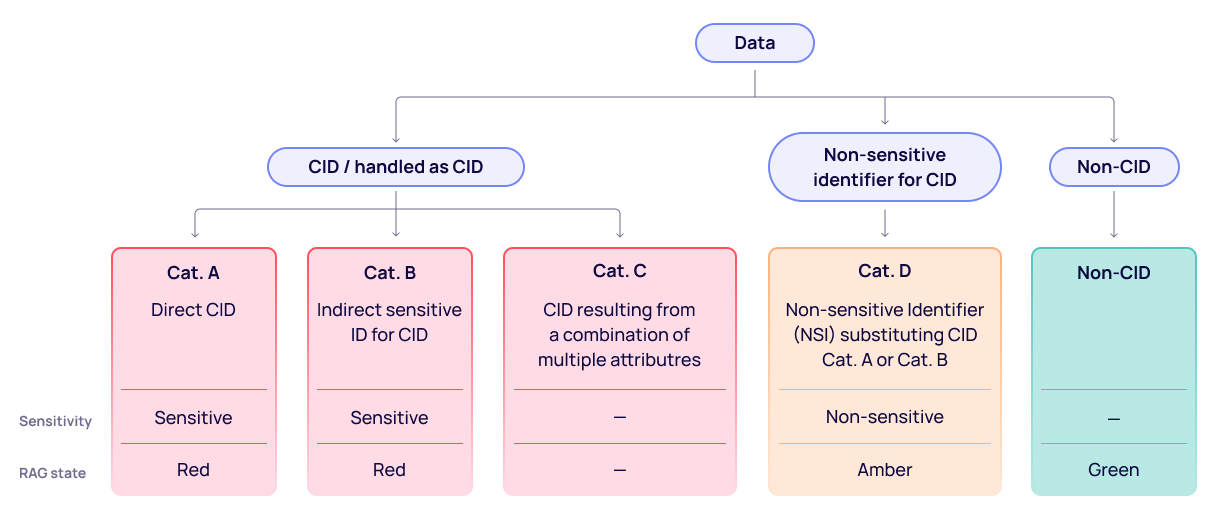
There will be instances where the most appropriate course of action is to simply redact the sensitive data - either removing the value completely, or replacing with "XXXX". Such an example of Cat A CID would be an individual’s account number or sort code. However, in other instances, it may be sufficient to substitute data fields containing CID with non-CID. For example, an individual’s income is non-sensitive data, but could potentially be used as an identifier for PII making it a Cat D attribute. Therefore, in order to preserve the utility of dataset while ensuring a degree of anonymization it may be appropriate to generalise the numeric value to a broader range. The masking and obfuscation techniques available are detailed in the Privacy Masks documentation.
Where identifying or sensitive information is spread across multiple linked columns, the dataset can be easily annotated to link the appropriate fields together. When annotated, Synthesized will learn to generate realistic entities as a whole, rather than independently generating individual attributes. In addition, Synthesized supports attribute-level pseudo-anonymization - where information relating to a data subject (e.g. the data subject’s name) is substituted with a pseudonym/identifier (e.g. token, mnemonic, etc.) in order to make it difficult (for a receiving unauthorized party) to attribute such information to an identifiable data subject. As an example, a dataset may contain first names, last names and email address made up of the combination of the two. In this case the sensitive nature of the data in the name fields can be substituted and a consistent email address generated. For a full list of possible entities that can be generated, see the Entity Annotation guide.
However, as explained in our blog posts How Weak Anonymization Became a Privacy Illusion and Three Common Misconceptions about Synthetic and Anonymized Data, when used in isolation anonymization techniques can still be broken and may not fully satisfy all compliance requirements. A more secure and robust option from the compliance point of view is to combine anonymization and then data generation from the anonymized data. That way, it can be guaranteed that there is no 1-to-1 mapping between entries in the original and synthetic data. In addition, the categories and data types are completely new semantically as well, i.e. there is no connection to the original data type.
|
If no annotations or masks are used in the configuration, the synthesizer will still generate data that can be linked to the original data. A simple example that illustrates this would be when synthesizing the following table with two columns.
Here, the synthesizer can generate a table with a different number of rows, and no single synthetic row corresponds to a single original row, but the actual catagories are still the same. In this sense, the synthetic data can be linked to the original data. And so when there is a column containing PII such as customer names instead of "Apple" and "Orange", the synthesizer should
be configured with annotations and/or
masks as to preserve the privacy (as described on this page).
An annotation such as Taking the above into account, Synthesized offers a significantly higher level of privacy compared to anonymization techniques alone making it impossible to determine original records from the synthetic data with any guarantee. |