Customise Model Training Loop
|
The full source code for this example is available for download here. |
This tutorial will detail how, through the use of callbacks, the SDK monitors and controls aspects of the training process. It will also demonstrate how to create and insert custom callbacks into the SDK’s training system. Custom callbacks can enable custom behaviour such as logging of training information (e.g. via tensorboard, to aid understanding and possibly fine-tuning), and add a custom progress bar (e.g. with different behaviour to the default bar).
For more information on what callbacks are and how to implement custom callbacks in tensorflow see Writing your own callbacks. To see a list of pre-made tensorflow callbacks see tf.keras.callbacks.
It is assumed that you have already worked through the introductory Single Table Synthesis tutorial and are familiar with the basics of how a machine learning model is trained.
Training
When training the deep generative model used by the SDK, there are a number of parameters that must be considered:
-
batch_size: the number of rows put through the model at each training step (i.e. the number of rows the model is trained on before the weights and biases are updated). SDK default is 1024. -
epochs: a specified number of batches. In the literature this is typically defined as being a complete cycle through the training data, i.e. num_batches_per_epoch = num_rows_in_dataset / batch_size. For performance reasons, this is not the definition that is used by the SDK. Instead, the SDK uses a fixed number of batches per epoch. The maximum number of epochs run in the SDK is 400. -
steps_per_epoch: the number of batches in an epoch. SDK default is 50
During a training cycle there are two places where custom code for monitoring and automated control of training should be run:
-
At the end of a batch
-
At the end of an epoch
The custom code is known as a "callback" and has a special structure. Creating custom callbacks is explained in tensorflow’s documentation.
Control of Training Cycle
Inside the SDK there are two ways that training can stop.
-
By default the SDK will run for 400 epochs with 50 steps per epoch, and 1024 rows of data per batch. That is 400 * 50 * 1024 = 20.48 million rows of data. When the model has been trained on this number of rows of data it will automatically stop training. If the dataset does not have this amount of data, the dataset will be repeated and the previous rows will be re-seen by the model until the above number has been reached.
-
In addition to the above, the SDK uses something called an EarlyStopping callback. This is a callback that runs at the end of each epoch and looks at the improvement in the output data compared to the expected output. If the quality has not improved for a specific number of epochs (in the SDK, this is 10 epochs) then the callback will stop model training, even if the number of rows specified in 1. above have not yet been reached. This is typically the mechanism that stops training in the SD and, if it is not and the training stopped because the epoch limit was reached, a warning is displayed since it is possible for the model to learn more with further training.
Monitoring and Progress Callbacks
Apart from automated stopping, callbacks are used in the SDK to monitor training and produce a progress bar. The SDK can train
for a maximum of 400 epochs, but often terminates training before this point due to the EarlyStopping callback. The progress bar
implemented by the SDK, therefore, does not display the fraction of the number of epochs run out of the maximum. Instead,
the SDK uses the maximum number of epochs since an improvement in data quality was seen (up to the maximum of 10,
at which point the EarlyStopping callback stops the training). For example, if two epochs have passed since a significant
improvement in data quality has occurred, the progress bar shows 2/10. If on epoch three an improvement is made, the
progress bar stays at two until such time as three complete epochs pass without improvement, when the progress bar then
moves to 3/10.
Custom callbacks
This section details and explains how to create custom callbacks, specifically an alternative progress bar callback based on number of steps/epochs, and the tensorboard callback to monitor training.
First, ensure required elements are imported:
from synthesized import HighDimSynthesizer, MetaExtractor
import synthesized_datasets as sd
import tensorflow as tf
df = sd.CREDIT.credit.load()Custom progress bar callback
First, create a custom callback:
# Specify colour and formatting via special ascii characters
LINE_START = "\033[38;5;47m"
LINE_END = "\033[39m"
# Extend the tensorflow's base callback class
class EpochProgressBar(tf.keras.callbacks.Callback):
def __init__(self, epochs=400, length=40):
"""
Args:
epochs: The number of epochs training will run for.
length: The length of the progress bar in number of characters.
"""
super().__init__()
self.length: int = length
self.epochs: int = epochs
self.completed_epochs = 0
def print_progress_bar(self):
fraction_complete = self.completed_epochs / self.epochs
num_bars_complete = int(fraction_complete * self.length)
num_bars_to_go = self.length - (1 + num_bars_complete)
bar = "╠" + ("█" * num_bars_complete) + (" " * num_bars_to_go) + "╣"
print(f"\rTraining epoch {self.completed_epochs} of {self.epochs} {LINE_START}{bar}{LINE_END} ", sep="", end="")
def on_train_begin(self, logs=None):
self.print_progress_bar()
def on_train_end(self, logs=None):
print("\nTraining finished.")
def on_epoch_end(self, epoch, logs=None):
self.completed_epochs += 1
self.print_progress_bar()Now use the custom callback during training:
synth = HighDimSynthesizer.from_df(df)
# Create custom callback object
epoch_progress_bar_callback = EpochProgressBar()
callbacks = [epoch_progress_bar_callback]
# Set verbose=0 to silence default callbacks (including default progress bar) otherwise both will show and interfere
synth.learn(df, callbacks=callbacks, verbose=0)Tensorboard callback
The tensorboard callback saves various internal tensorflow metrics to a file. The metrics can then be used by the tensorboard application to then display the results in a nice web-based interface. It is assumed this example is run as a jupyter notebook. If so, the Tensorboard notebook extension is required:
%load_ext tensorboardWhen using the Tensorboard callback, a directory to store the logs must be created:
synth = HighDimSynthesizer.from_df(df)
log_dir = "./logs/tensorboard"
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)Finally, the callback can be provided as an argument to the fit method. In notebooks, use the %tensorboard line
magic as below to display the Tensorboard UI:
# Train the synthesizer with the new callback
%tensorboard --logdir logs/tensorboard
synth.learn(df, callbacks=[tensorboard_callback])Alternatively, the same command can be run in the terminal
tensorboard --logdir ./logs/tensorboardThis should start tensorboard and host it on localhost:6006, giving a message in the terminal similar to:
TensorBoard 2.9.1 at http://localhost:6006/ (Press CTRL+C to quit)Opening "http://localhost:6006/" in a web-browser should then display the tensorboard UI, and should look something like:
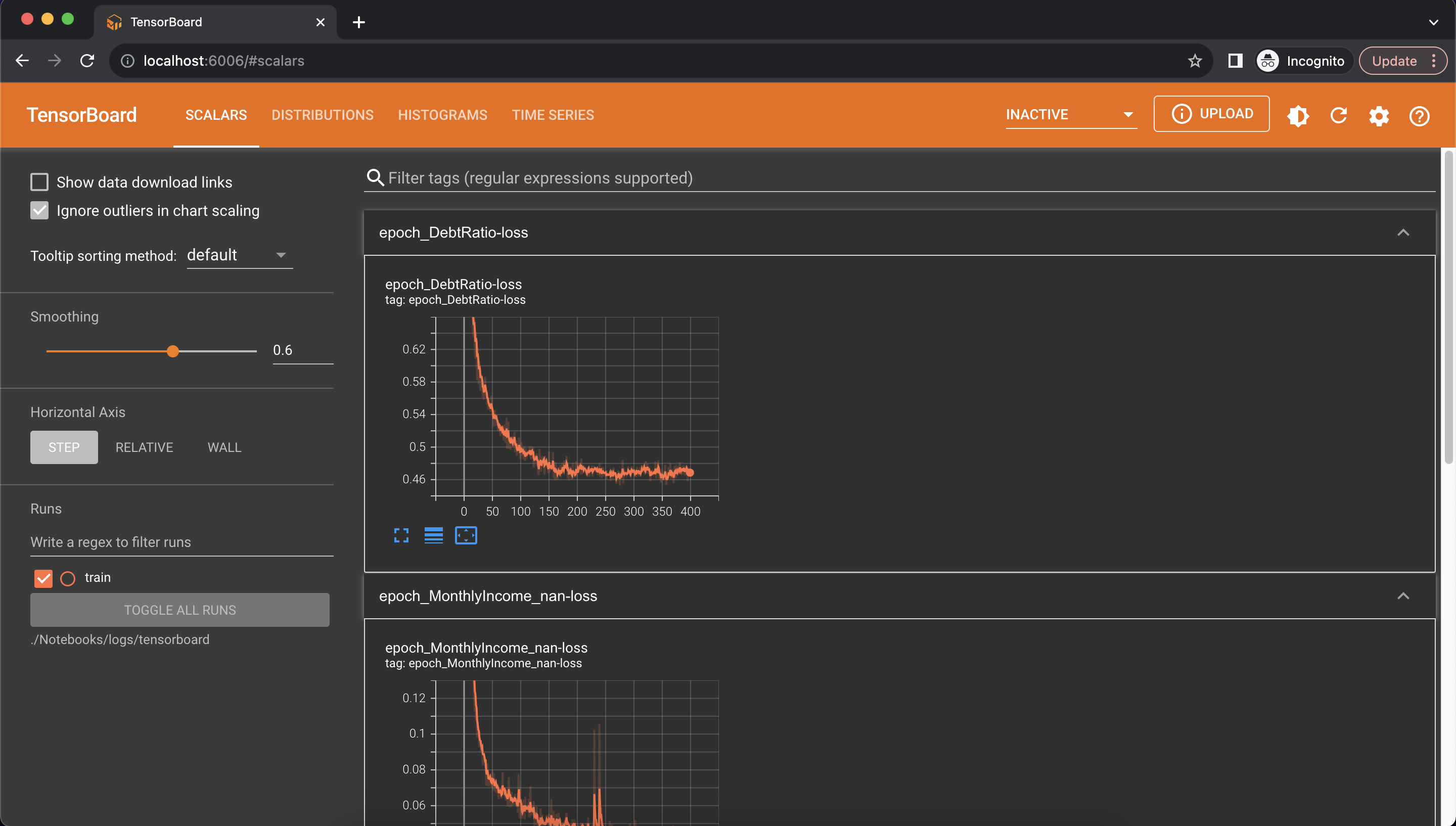
|
For SDK v2.8 and below inclusive specifying custom callbacks causes the default callbacks to be removed. This means the EarlyStopping callback is not used and training occurs for the full default 400 epochs, which can cause training times to take a lot longer than you may be used to. For v2.8 and under, the default callbacks can be created and included by doing the following: |