Single Table Synthesis
|
The full source code for this example is available for download here along with the example dataset. |
In this tutorial the most important features of the Synthesized SDK are explained using examples of a complete end-to-end generation of synthetic data from an original dataset. The examples demonstrate how an end-to-end synthesis can be achieved using the default parameters, as well as going into more detail on how non-default settings can be configured by the user at each stage of the process. The generative models leveraged by the SDK have been tuned on a wide variety of datasets and data types, meaning that the "out-of-the-box" behaviour of the SDK is performant and produces synthetic data statistically similar to the original. However, where custom scenarios and constraints are required a user can define a custom configuration when using the SDK.
Fitness Dataset
This example will use a modified public dataset from Kaggle detailing the attendance of a range of fitness classes available at a gym:
import pandas as pd
df = pd.read_csv("fitness_data.csv")
dfbooking_id months_as_member weight days_before day_of_week time category attended membership 0 1 17 79.56 8 3 PM Strength 0 Anytime 1 2 10 79.01 2 1 AM HIIT 0 Anytime 2 3 16 74.53 14 7 AM Strength 0 Weekend 3 4 5 86.12 10 5 AM Cycling 0 Anytime 4 5 15 69.29 8 4 AM HIIT 0 Anytime ... ... ... ... ... ... ... ... ... ... 1495 1496 21 79.51 10 5 AM HIIT 0 Anytime 1496 1497 29 89.55 2 1 AM Strength 0 Anytime 1497 1498 9 87.38 4 2 AM HIIT 0 Anytime 1498 1499 34 68.64 14 7 AM Aqua 0 Weekend 1499 1500 20 94.39 8 4 AM Cycling 1 Anytime [1500 rows × 9 columns]
This dataset has a number of interesting features:
-
The column
booking_idis an enumerated column, i.e. it increases in constant sized steps from a starting value -
The column
day_of_weekcommunicates what day of the week the class was held, but as an integer -
There is a
membershipcolumn, communicating what type of plan the member is on-
"Anytime" members can attend classes on any day of the week
-
"Weekend" members can only attend classes on a Saturday or Sunday
-
This tutorial will demonstrate how the SDK can be used create synthetic data with the
same statistical fidelity as the original dataset, and new values of booking_id in order to supplement the original data.
This is a common task within an organisation, especially where the volume of the original dataset is small.
Before any synthetic data is generated, it is best practice to perform some exploratory data analysis (EDA) to gain a deeper understanding of the dataset. For example, EDA could be done to determine whether there are missing values, understand the distribution of outliers or calculate/plot any univariate and multivariate statistics that may aid in the development of any hypothesis testing. This is by no means a comprehensive list of techniques and tools encompassed within EDA and the actual EDA process is highly individual and dependent on how the synthetic data will be leveraged downstream.
Simple Synthesis
The first step is to extract the metadata from the original dataset. The metadata stores the information regarding the
inferred data types that will be used during model training. The MetaExtractor object can be used to extract the meta data,
which is then available for inspection
from synthesized import MetaExtractor
df_meta = MetaExtractor.extract(df)
df_meta.children[<Scale[int64]: Integer(name=booking_id)>, <Scale[int64]: Integer(name=months_as_member)>, <Ring[float64]: Float(name=weight)>, <Scale[int64]: Integer(name=days_before)>, <Scale[int64]: Integer(name=day_of_week)>, <Nominal[object]: String(name=time)>, <Nominal[object]: String(name=category)>, <Ring[int64]: IntegerBool(name=attended)>, <Nominal[object]: String(name=membership)>]
More information on the metadata, including how to override the default behaviour, can be found in the documentation.
Following the metadata extraction, a HighDimSynthesizer object is created. The HighDimSynthesizer is our generative
model for tabular data, using a mixture of deep generative statistical models. It is trained on the original dataset
and used to generate the synthetic data
from synthesized import HighDimSynthesizer
synth = HighDimSynthesizer(df_meta)The intelligent inference built-in to the SDK will determine how each column should be modelled using the metadata extracted
in the previous step. The HighDimSynthesizer object can be inspected in order to examine how each column will be modelled
synth._df_model.children[Enumeration(meta=<Scale[int64]: Integer(name=booking_id)>), KernelDensityEstimate(meta=<Scale[int64]: Integer(name=months_as_member)>), KernelDensityEstimate(meta=<Ring[float64]: Float(name=weight)>), KernelDensityEstimate(meta=<Scale[int64]: Integer(name=days_before)>), Histogram(meta=<Scale[int64]: Integer(name=day_of_week)>), Histogram(meta=<Nominal[object]: String(name=time)>), Histogram(meta=<Nominal[object]: String(name=category)>), Histogram(meta=<Ring[int64]: IntegerBool(name=attended)>), Histogram(meta=<Nominal[object]: String(name=membership)>)]
There are three types of models available as part of the SDK
-
KernelDensityEstimatefor continuous variables -
Histogramfor categorical variables -
Enumerationfor variables that increase monotonically in constant step sizes
It is worth noticing that even though the day_of_week column is stored as an Integer meta (and int dtype
in the original data), the intelligent inference in the HighDimSynthesizer has correctly determined that it should be
modelled categorically. More information on the models used by the HighDimSynthesizer is available in the
documentation
The distributions and correlations in the original data can now be learnt by the deep generative engine utilised by the HighDimSynthesizer
synth.learn(df)before the trained HighDimSynthesizer instance is used to generate data
df_synth = synth.synthesize(1000)
df_synthbooking_id months_as_member weight days_before day_of_week time category attended membership 0 1 12 90.066933 10 5 AM HIIT 1 Anytime 1 2 6 103.90821 4 2 PM HIIT 0 Anytime 2 3 25 69.947906 2 1 AM HIIT 0 Anytime 3 4 20 67.090652 8 3 AM Cycling 0 Anytime 4 5 4 97.576874 8 4 PM HIIT 0 Anytime ... ... ... ... ... .... .. ... ... ... 995 996 14 80.107185 2 1 PM HIIT 0 Anytime 996 997 21 69.503784 14 7 AM HIIT 1 Weekend 997 998 23 71.233406 7 4 AM Cycling 0 Anytime 998 999 39 68.872650 6 1 AM Strength 1 Anytime 999 1000 29 73.566185 4 2 PM Strength 1 Anytime [1000 rows × 9 columns]
|
A new synthetic DataFrame is generated each time the |
Before performing any evaluation, by simply visually inspecting the synthetic dataset it is clear that the values of
booking_id have been sampled from the original dataset, rather than any new ones actually being created. The next stage
is to evaluate the statistical quality of the synthetic data in order to determine which aspects of the training process
need reconfigured, along with configuring the ability to synthesize new values in "booking_id".
Evaluation
When evaluating the quality of synthetic data, there are generally three perspectives to consider:
-
Statistical Quality
-
Predictive Utility
-
Privacy
It is recommended best practice to evaluate the statistical quality of the synthetic data (i.e. its fidelity compared to the original data) before considering other metrics, to ensure that the synthetic data quality meets the requirements of the user.
Here, the focus will be on evaluating only the statistical quality of the synthetic data. However, the documentation details the comprehensive set of tools which can be combined to form a framework that can be used to evaluate the quality of the data across the three key dimensions listed above.
A simple first step is to analyse whether similar numbers of missing values are present in the original and synthetic dataframes. Where there are no missing values in the original, it should be confirmed there are none in the synthetic
pd.concat([df.isna().sum(), df_synth.isna().sum()], axis=1, keys=["original_nan_count", "synthetic_nan_count"])original_nan_count synthetic_nan_count booking_id 0 0 months_as_member 0 0 weight 20 28 days_before 0 0 day_of_week 0 0 time 0 0 category 0 0 attended 0 0 membership 0 0
Next, the Assessor class can be utilized in order to compare the univariate and bivariate statistics across the synthetic
and original datasets. As an initial sanity check, the distributions of the continuous and
categorical features in the original and synthetic datasets are visually compared (excluding the "booking_id" feature
since this is an enumerated unique ID):
from synthesized.testing import Assessor
df_meta.pop("booking_id")
assessor = Assessor(df_meta)
assessor.show_distributions(df, df_synth)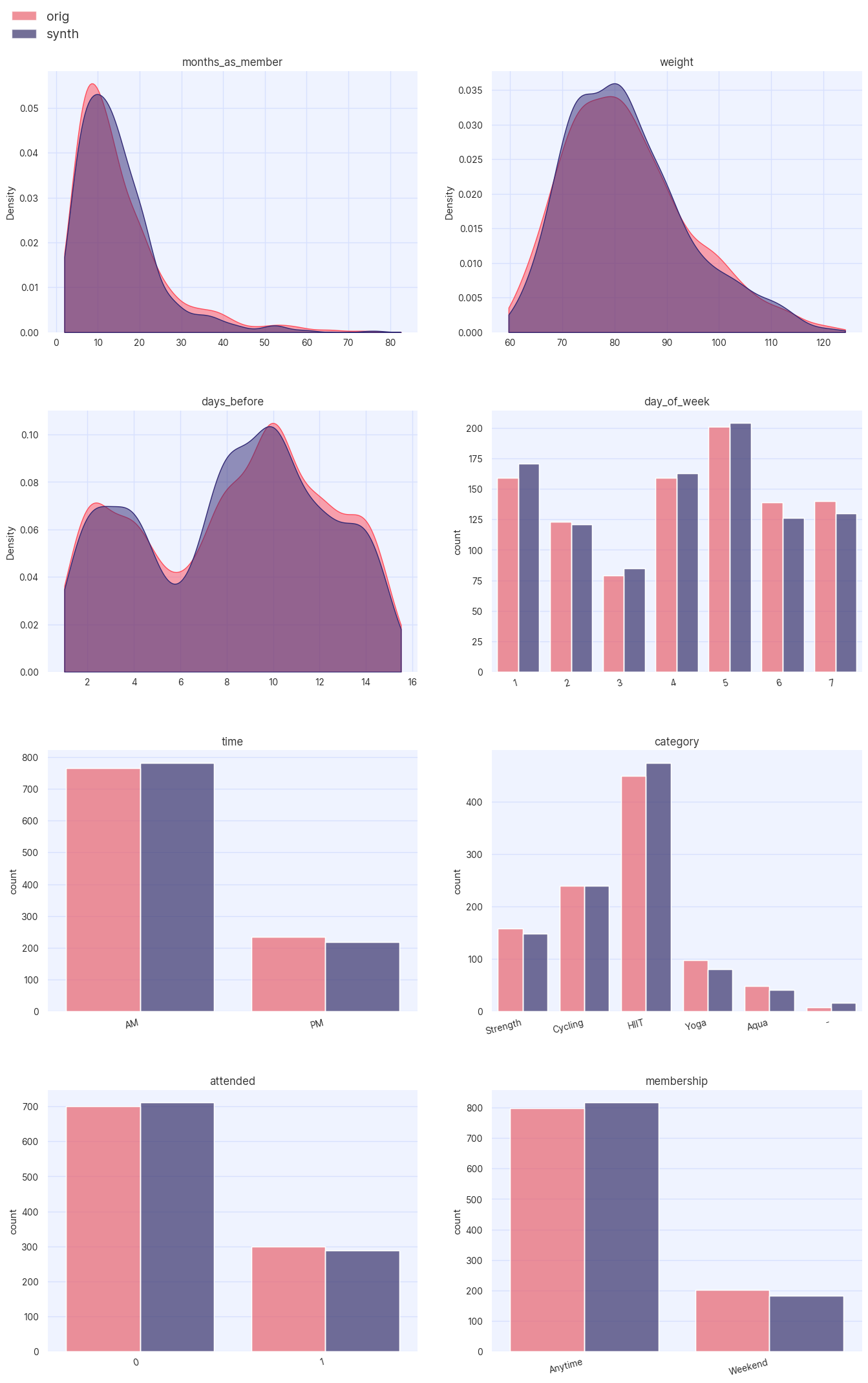
A quick visual inspection confirms that the synthetic data is qualitatively similar to the original, however by calculating appropriate distances between distributions in the two datasets the user can better quantify the statistical quality of the data. For continuous distributions, the Kolmogorov-Smirnov (KS) distance is calculated
assessor.show_ks_distances(df.drop(columns=["booking_id"]), df_synth.drop(columns=["booking_id"]))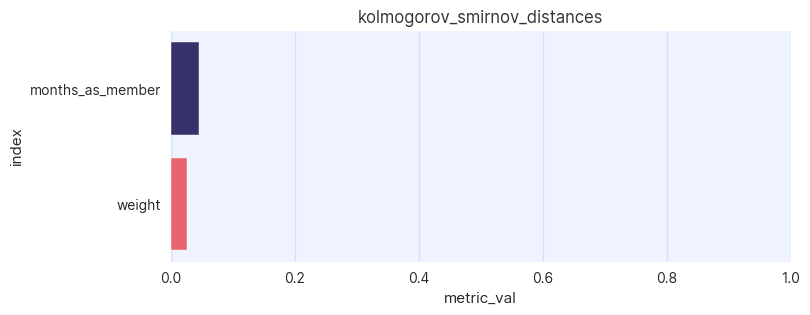
while for categorical distributions the earth mover’s distance (EMD) is shown
assessor.show_emd_distances(df, df_synth)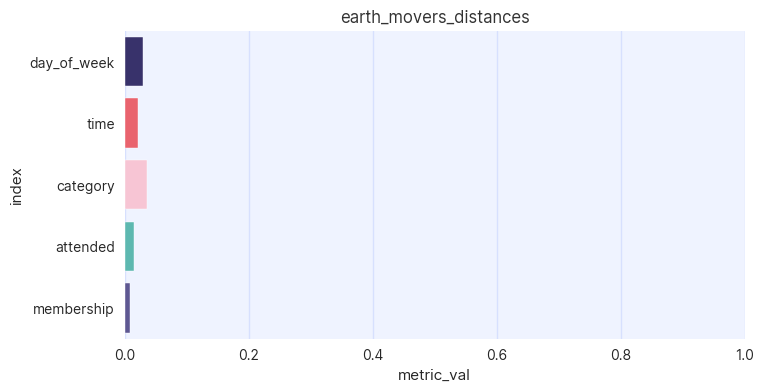
Analysis can also be extended to two column correlation and interaction metrics. For example, when examining the correlations across all ordinal variables it is appropriate to use the Spearman-rho correlation
assessor.show_spearman_rho_matrices(df, df_synth)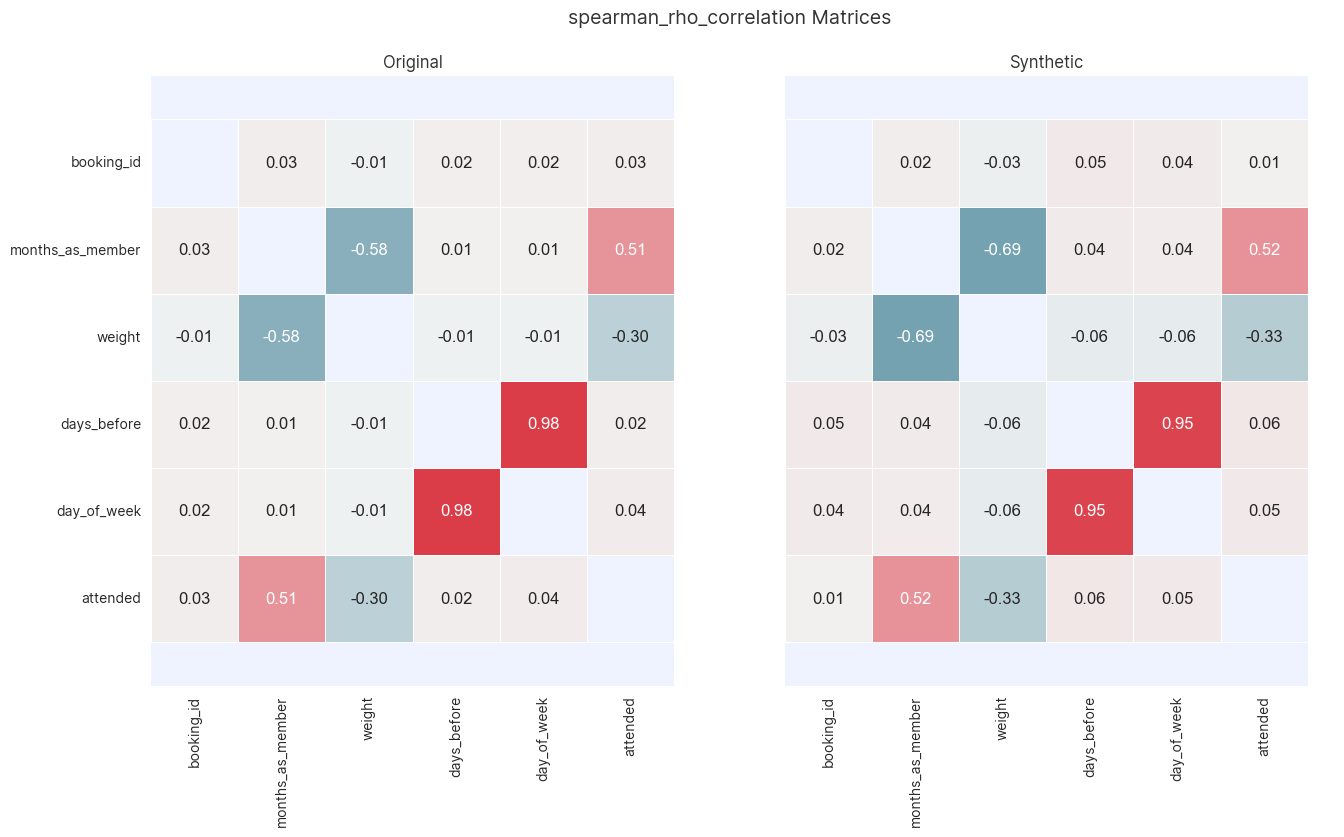
A full description of the metrics available in the Assessor module can be found in the
documentation
Finally, certain constraints may be present in an original dataset, such as business rules, that may be required to be
adhered in the synthetic dataset. Recall that in the original data, "Anytime" membership allowed
gym users to attend a class on any day of the week while "Weekend" members could only book classes on a Saturday or
Sunday. By plotting a cross-table of the number of times a value in one column appears beside a value in another, it is possible
to determine whether this business logic has been adhered to
from synthesized.testing.plotting import plot_cross_tables
plot_cross_tables(df, df_synth, "membership", "day_of_week")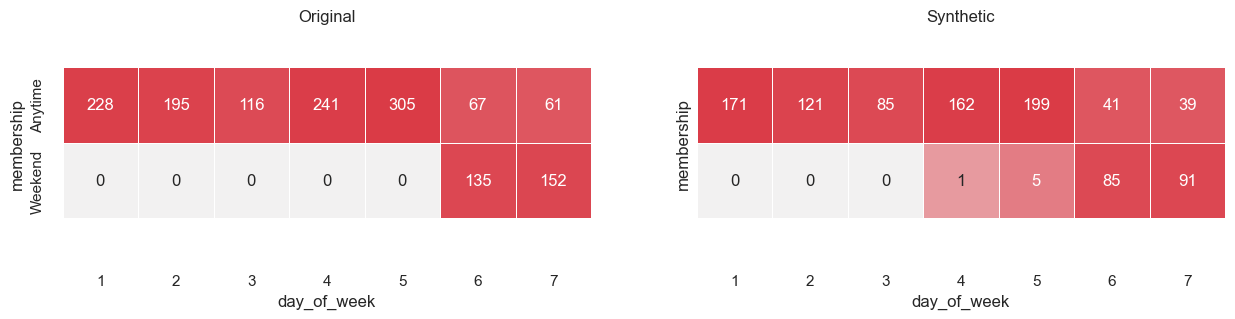
|
The above analysis should not be considered exhaustive and the evaluation of the statistical quality of the data should be informed by the downstream problem at hand and the EDA of the original dataset prior to any synthesis jobs being run. |
Although the statistical quality of the synthetic data is very good, there are a few instances where the business logic regarding membership is not respected. When this occurs, it is usually due to limited training data. In the next section, a custom synthesis job will be run which will enforce this business logic.
Custom Synthesis Configuration
While the statistical quality of the synthetic data generated through the default configuration is very good, it did not meet all the requirements laid out at the beginning of the tutorial. In this section, a custom configuration will be applied such that:
-
The data is constrained to follow the correct business logic across the
booking_idandmembershipcolumns -
New values of
booking_idare generated
To accomplish the first of these goals, the Associations class will be used in order to generate custom
scenarios within the synthetic data.
from synthesized.metadata.rules import Association
df_meta_2 = MetaExtractor.extract(df, associations=[Association(associations=["membership", "day_of_week"])])The Association class will automatically detect how two variables are related, model their joint-probability and ensure
that "impossible" events (e.g. a gym user with a "Weekend" membership attending a class on a weekday) do not appear
in the synthetic data. More information on the Association class, as well as other rules and constraints, can be
found in the documentation.
Secondly, to ensure that new values are created in the booking_id column, a type_override is defined when instantiating
an instance of the HighDimSynthesizer to ensure that the column is modelled properly. As described in Overrides,
a starting value and step size can be explicitly defined when using the Enumeration model
from synthesized.model.models import Enumeration
synth_2 = HighDimSynthesizer(df_meta_2, type_overrides=[Enumeration(df_meta_2["booking_id"], start=1501, step=1)])As before, the model is trained
synth_2.learn(df)and used to generate synthetic data
df_synth_2 = synth_2.synthesize(1000)
df_synth_2booking_id months_as_member weight days_before day_of_week time category attended membership 0 1501 30 75.630997 10 5 AM Cycling 1 Anytime 1 1502 6 80.820389 4 1 AM HIIT 0 Anytime 2 1503 6 75.162788 6 3 PM Cycling 0 Anytime 3 1504 5 110.46816 12 6 AM HIIT 0 Weekend 4 1505 20 69.400856 14 7 AM Yoga 1 Weekend ... ... ... ... ... ... ... ... ... ... 995 2496 6 85.863640 4 2 PM Cycling 0 Anytime 996 2497 10 75.686485 8 4 AM Strength 0 Anytime 997 2498 16 74.846046 12 6 AM Aqua 0 Weekend 998 2499 9 92.433426 4 2 PM HIIT 0 Anytime 999 2500 20 80.090515 12 6 AM HIIT 0 Anytime [1000 rows × 9 columns]
In contrast to the default set-up, the new configuration allows the generation of new values for booking_id. A full evaluation of the
statistical quality of the new synthetic dataset should once again be completed as in the previous section.
To demonstrate that the use of the Associations class has constrained the synthetic data to follow the correct business logic,
with regards to the membership and booking_id column, the cross tables are plotted once again
plot_cross_tables(df, df_synth_2, "membership", "day_of_week")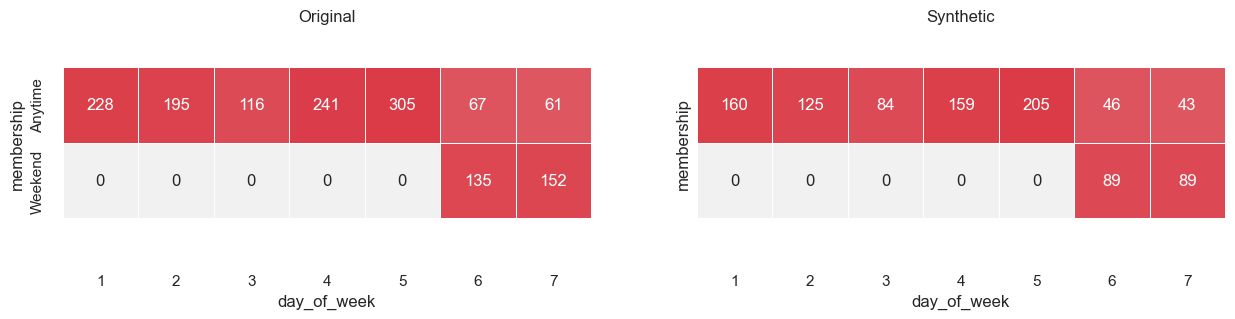
With the custom configuration, the HighDimSynthesizer has adhered to the correct business logic by only producing data points where
"Weekend" members can only attend weekend classes.