Platform Architecture
Understand the high-level architecture and components that power the platform’s data masking, generation, and subsetting capabilities.
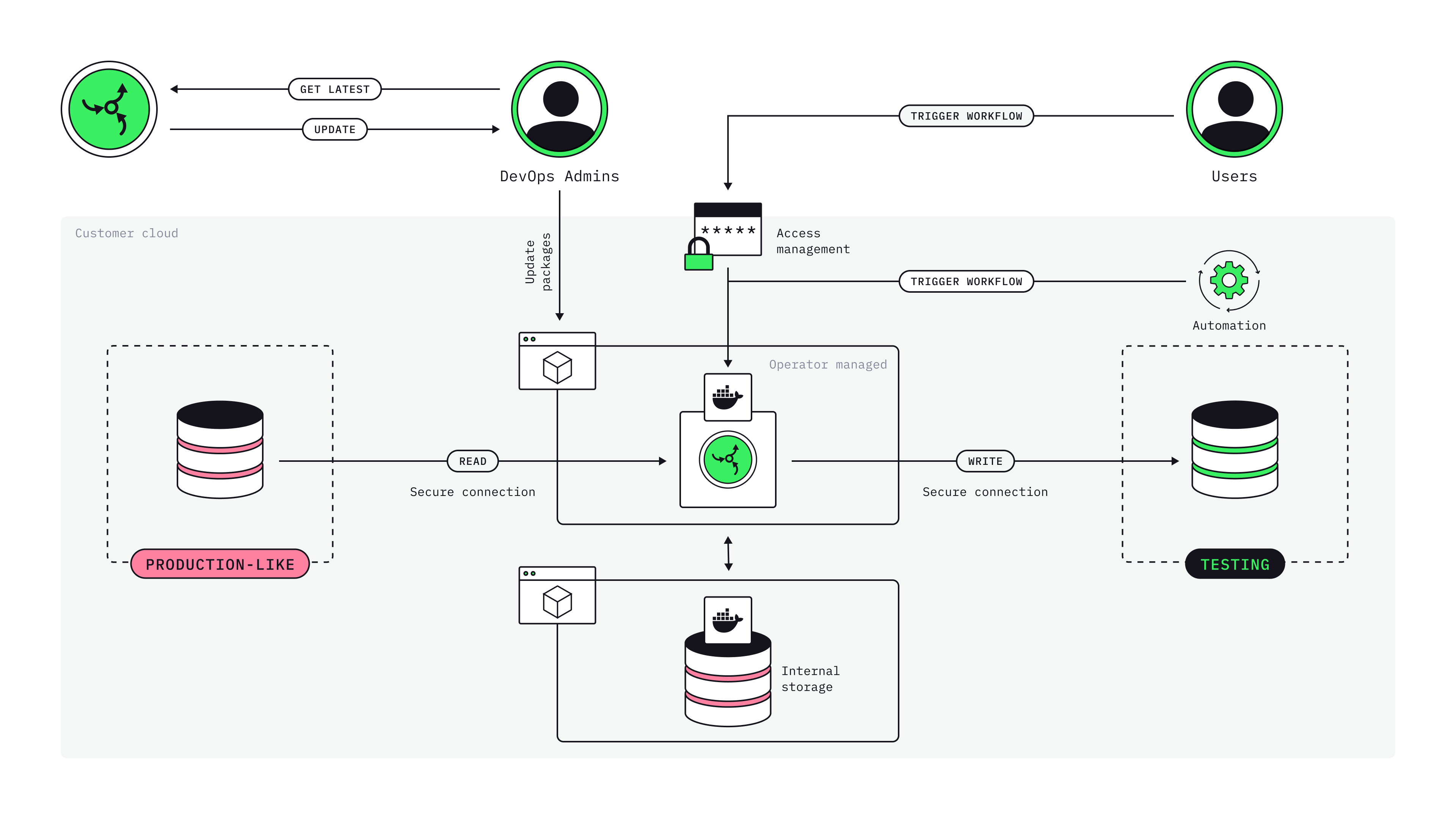
System Components
1. Backend Server
The central orchestration engine that manages the entire platform.
| Responsibility | Description |
|---|---|
Workflow Management |
Manages workflow configurations and templates |
Scheduling & Coordination |
Schedules and coordinates transformations |
Web UI & API |
Provides the web UI and REST API endpoints |
Authentication & Authorization |
Handles user authentication and RBAC |
Metadata Storage |
Stores workflow history and execution logs |
| Deployment |
Docker container or Kubernetes pod |
| Scaling |
Vertical scaling for metadata operations |
2. Worker Nodes
Distributed workers that execute transformations in parallel.
| Function | Details |
|---|---|
Data Reading |
Read data from source databases via JDBC |
Transformation |
Apply transformers to each record/batch |
Data Writing |
Write transformed data to destinations |
Progress Reporting |
Report progress back to the backend |
Horizontal Scaling |
Can scale horizontally for parallelization |
| Deployment |
Can run as separate containers/processes for scaling |
| Learn more |
3. CLI (Command-Line Interface)
Standalone mode for running transformations without the backend server.
See: CLI Overview
4. Metadata Database
PostgreSQL database storing:
-
Workflow configurations
-
User accounts and permissions
-
Execution history and logs
-
Project and workspace data
-
Scheduled job definitions
| Deployment |
PostgreSQL container or managed database service |
5. Web UI (Frontend)
React-based web interface for:
-
Creating and editing workflows
-
Running and monitoring transformations
-
Managing data sources and projects
-
User administration
-
Viewing execution logs
| Deployment |
Served by backend or as static files |
Key Design Principles
1. Referential Integrity First
The platform automatically:
-
Discovers foreign key relationships
-
Processes tables in dependency order
-
Ensures all foreign keys reference valid primary keys
-
Handles virtual foreign keys defined in configuration
2. Schema Preservation
The destination schema matches the source:
-
Same table and column names
-
Same data types
-
Same constraints (PRIMARY KEY, UNIQUE, CHECK)
-
Same indexes (created after data load)
3. Scalability
Multiple strategies for handling large datasets:
-
Batch Processing: Process data in configurable batch sizes
-
Streaming: Stream data from source to destination
-
Incremental Updates: Only process changed rows
4. Extensibility
Customize behavior through:
-
Transformers: 50+ built-in, plus custom JavaScript
-
Scripts: Pre/post SQL scripts
-
Plugins: Custom Java transformers (advanced)
-
APIs: REST API for automation
Modes of Operation
MASKING Mode
-
Reads all rows from source
-
Applies transformers to specified columns
-
Preserves row count and IDs
-
Writes to destination
Use: Anonymize production data for dev/test
See: How Masking Works
GENERATION Mode
-
Reads schema from destination
-
Generates new rows based on configuration
-
Creates realistic synthetic data
-
Maintains relationships
Use: Create test data from scratch
See: How Generation Works
KEEP Mode
-
Applies WHERE filters to select rows
-
Automatically follows foreign keys
-
Includes related data
-
Preserves referential integrity
Use: Extract smaller representative datasets
See: How Subsetting Works